AI-Tools CanIRun.ai kann automatisch die Hardware-Spezifikationen der Nutzer im Browser erkennen, um abzuschätzen, welche LLM-Modelle auf dem System laufen können und wie schnell die Inferenz ist. Interessierte Nutzer können es ausprobieren und kennenlernen.
(Frühere Zusammenfassung: Clawdbot, der göttliche AI-Helfer, der den Mac mini 24/7 ausverkauft macht)
(Hintergrund: Nicht blind dem Trend folgen bei OpenClaw, die Krabben-AI ist stark, aber nicht unbedingt passend für dich)
Inhaltsverzeichnis
Toggle
- Die kleinen Schwächen von CanIRun.ai
- Alternative Kommandozeilen-Tools: llmfit
- Das, was die Community am meisten will
Möchten Sie lokale LLM-Modelle selbst installieren? Das häufigste Anfängerproblem ist: Was kann mein Computer überhaupt ausführen? Dieser Artikel stellt ein Tool vor, das kürzlich in der Hacker News Community für Diskussionen gesorgt hat: CanIRun.ai.
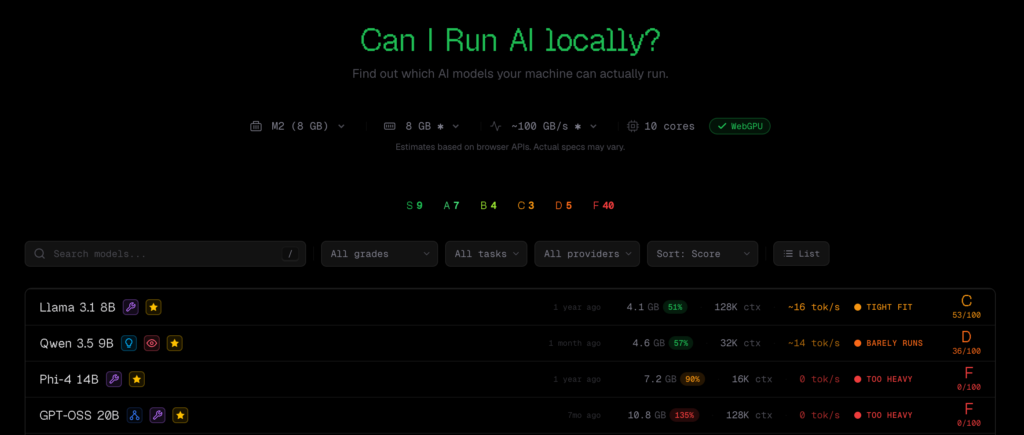
CanIRun.ai ist ein reines Web-Tool, das ganz einfach funktioniert: Du öffnest den Browser, und es erkennt automatisch über die WebGPU API dein GPU-Modell und den Speicher. Basierend auf Parameteranzahl, Quantisierungsstufen (Q4_K_M, Q8_0, F16 etc.) und Speicherbandbreite schätzt es die Ausführbarkeit und Inferenzgeschwindigkeit (Token/s) jedes Modells ab und zeigt die Ergebnisse mit einer Bewertung von S bis F.
Das Spektrum reicht von ultra-leichten Modellen mit 0,8 Milliarden Parametern bis zu riesigen MoE (Mixture of Experts)-Modellen mit 1 Billion Parametern. Die Daten stammen von gängigen lokalen Inferenz-Tools wie llama.cpp, Ollama und LM Studio.
Die kleinen Schwächen von CanIRun.ai
Obwohl das Konzept des Tools in der Community gut ankommt, gibt es auch Kritik. Diese konzentriert sich auf zwei Punkte: unvollständige Hardware-Unterstützung und Diskrepanzen zwischen Schätzung und Realität.
Das Fehlen bestimmter Hardware-Modelle ist das häufigste Problem. RTX Pro 6000, RTX 5060 Ti 16GB, verschiedene Laptop-GPUs sind nicht gelistet. Bei Apple-Chips ist zwar eine Liste vorhanden, aber nur bis zu 192GB RAM. Der M3 Ultra unterstützt tatsächlich bis zu 512GB.
Bei den Schätzungen gibt es auch Abweichungen: Nutzer haben getestet und festgestellt, dass die Ergebnisse manchmal nicht mit den von CanIRun.ai gelieferten Resultaten übereinstimmen. Fälle, in denen das System sagt „nicht möglich“ obwohl es tatsächlich läuft, tauchen immer wieder auf. Das führt dazu, dass manche Nutzer die Ergebnisse gar nicht mehr vertrauen.
Obwohl die Webseite noch Verbesserungsbedarf hat, ist sie für Anfänger dennoch eine schnelle Orientierungshilfe, um die eigene Hardware einzuschätzen.
Kommandozeilen-Alternative: llmfit
In der Community wird auch das Tool llmfit empfohlen: ein Kommandozeilen-Programm, das direkt System-Tools wie nvidia-smi aufruft, um präzise GPU-Infos zu erhalten. Es ist nicht auf Browser-APIs angewiesen und gilt als praktischer und genauer als die Web-Version.
Allerdings bringt llmfit eine andere Diskussion auf: Einige Nutzer sind überrascht, dass es die GPU-Modelle ohne explizite Berechtigungen so genau erkennt. Das berührt die sensible Thematik von Browser-Fingerprinting und Hardware-Privatsphäre: Wenn eine Webseite über WebGPU deine Grafikkarte erkennen kann, wie werden diese Daten genutzt?
Ein Nutzer schlägt vor, diese Funktionalität direkt in Ollama zu integrieren, sodass Nutzer per Kommandozeile automatisch passende Modelle basierend auf ihrer Hardware auswählen können – ohne manuelles Nachschlagen.
Das, was die Community am meisten will
Das Feedback zeigt, dass die Hauptbeschränkung von CanIRun.ai nicht nur die Schätzgenauigkeit ist, sondern auch die eingeschränkte Bewertungsdimension. Nutzer wollen wissen: Welches Modell bietet auf meiner Hardware das beste Verhältnis von Qualität und Geschwindigkeit? Das Tool kann nur sagen „läuft“, aber nicht, ob es auch gut läuft.
Die Community wünscht sich eine Bewertungsskala für Modellfähigkeiten, die mit der Hardware-Schätzung kombiniert wird, um eine umfassendere Entscheidungsgrundlage zu bieten. Weitere technische Verbesserungen wären: die Integration von CPU-Speicher-Sharing (damit GPUs mit wenig VRAM den Systemspeicher nutzen können), Unterstützung für KV-Cache-Disaggregation und Korrekturen bei der Berechnung von MoE-Modellen.
Insgesamt ist die Richtung des Tools richtig, der Marktbedarf besteht: Für den durchschnittlichen Nutzer ist der Einstieg in lokale KI noch zu hoch. Schnell zu erkennen, „Was kann mein Rechner ausführen?“ ist eine echte Notwendigkeit. CanIRun.ai trifft diesen Punkt, braucht aber noch Feinschliff.
Disclaimer: The information on this page may come from third parties and does not represent the views or opinions of Gate. The content displayed on this page is for reference only and does not constitute any financial, investment, or legal advice. Gate does not guarantee the accuracy or completeness of the information and shall not be liable for any losses arising from the use of this information. Virtual asset investments carry high risks and are subject to significant price volatility. You may lose all of your invested principal. Please fully understand the relevant risks and make prudent decisions based on your own financial situation and risk tolerance. For details, please refer to
Disclaimer.