A medida que las cargas de trabajo de inferencia evolucionan de clústeres de prueba a aplicaciones empresariales reales, la solución óptima por defecto deja de ser “todo centralizado en centros de datos de ultra gran escala”. Este artículo examina la lógica por capas de nodos edge, centros de datos regionales y clústeres centrales desde las perspectivas de latencia, ancho de banda, disponibilidad y cumplimiento. Explica los puntos clave en la partición de tareas, límites de datos y gobernanza operativa dentro de topologías híbridas, y ofrece una visión comparativa frente a la cadena de infraestructura de IA más amplia.
Los discursos públicos suelen equiparar la potencia de hash de IA con “centros de datos de ultra gran escala más GPU de gama alta”. Para el entrenamiento y ciertos escenarios de inferencia centralizada, esta definición suele aplicarse. Infraestructura de IA incluye solicitudes de inferencia ampliamente distribuidas, sensibles a la latencia y que requieren que los datos permanezcan dentro del dominio, mientras que las interrupciones de red o la congestión máxima son inaceptables. En estos casos, la topología de inferencia se convierte en un problema de infraestructura: la potencia de hash debe estar disponible y ubicada en “la posición geográfica adecuada y la capa de red correcta”.
Si la infraestructura de IA se concibe como una cadena continua, que va desde el nivel de chip hasta servicios y gobernanza, este artículo se centra en topología y formas de despliegue: cómo asignar computación y datos entre edge, región y capas centrales para equilibrar latencia, coste, disponibilidad y cumplimiento. Temas upstream como energía, packaging y HBM son más apropiados para debates del lado de la oferta, mientras que el enrutamiento multimodelo a nivel empresarial y los detalles de gobernanza de agentes complementan las operaciones de producción.
Por qué discutir la “topología de inferencia distribuida”
La inferencia centralizada ofrece operaciones unificadas, escalado flexible y alta utilización de recursos. Sin embargo, cuando el negocio presenta alguna de las siguientes características, las decisiones de topología impactan significativamente en la experiencia y el coste:
-
Fuertes restricciones de latencia: El control industrial, la interacción en tiempo real, los enlaces de audio/video y las ubicaciones de retail offline son sensibles a la latencia final; trayectorias de retorno demasiado largas amplifican el jitter.
-
Soberanía y residencia de datos: Escenarios como información personal, transacciones financieras, servicios gubernamentales y salud suelen requerir que los datos permanezcan dentro del dominio, fronteras o regiones designadas.
-
Ancho de banda de retorno y coste: Endpoints masivos suben datos brutos continuamente a la inferencia central, haciendo que la red backbone y las tarifas de salida sean posibles motores principales de costes.
-
Disponibilidad y resiliencia: Ante fallos de red de área amplia, fluctuaciones DNS o congestión entre regiones, las arquitecturas puramente centrales son más propensas a riesgos en cascada de “indisponibilidad total del sitio”.
-
Red offline o débil: Entornos como minas, barcos y ciertos sitios de manufactura requieren capacidad operativa local, en vez de dependencia fuerte de conectividad online en tiempo real.
Estos desafíos no pueden resolverse simplemente con “modelos centrales más potentes”, ya que sus problemas centrales radican en la distancia física, rutas de red y límites de políticas—no en la potencia máxima de hash de una sola inferencia.
Despliegue por capas: qué resuelven edge, región y centro
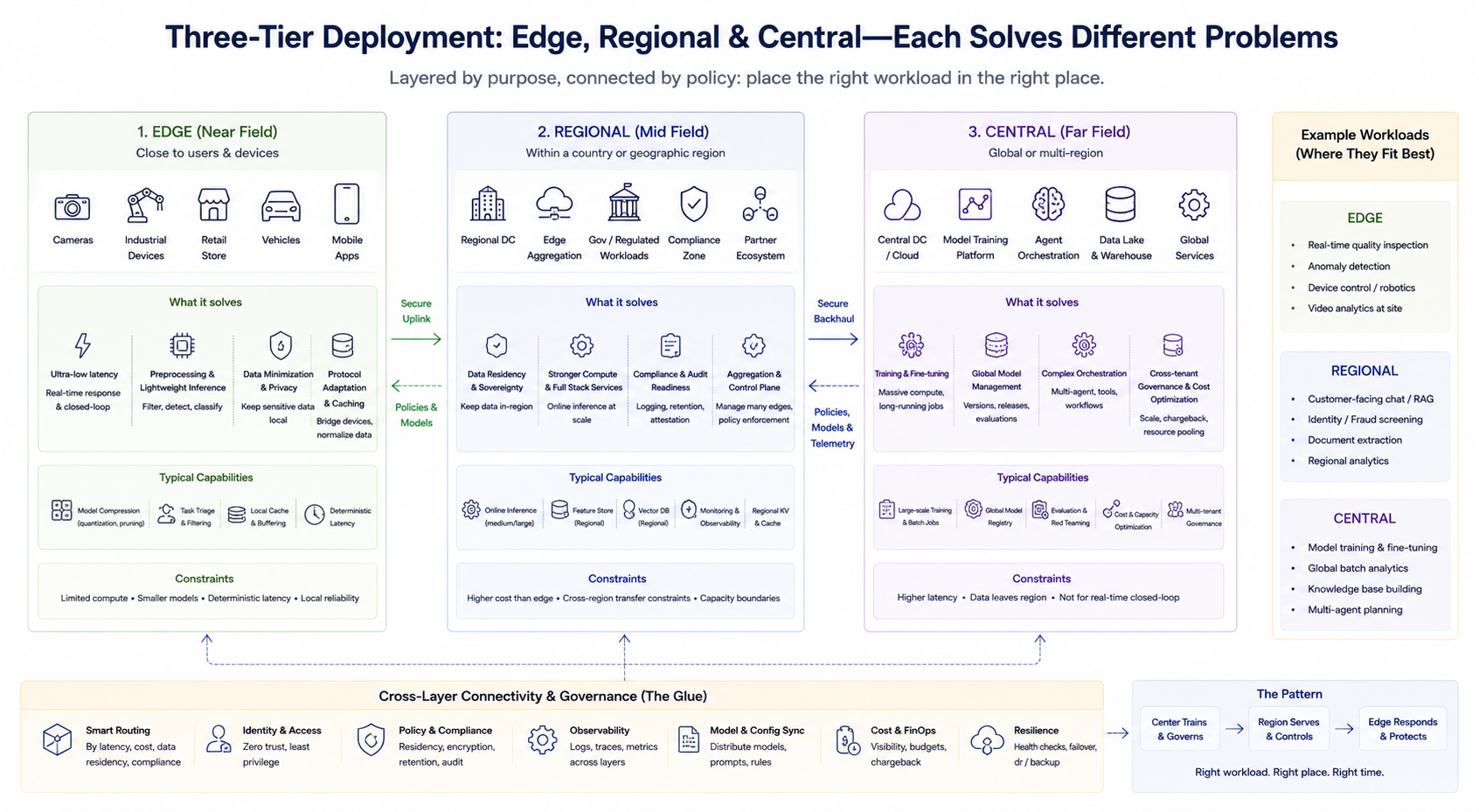
El enfoque ingenieril típico no es una elección binaria, sino una combinación por capas. Un framework simplificado ayuda a clarificar las responsabilidades de cada capa (la nomenclatura específica puede variar según el proveedor):
Capa edge (campo cercano)
Ubicada cerca de usuarios o dispositivos, esta capa gestiona preprocesamiento de baja latencia, inferencia ligera, caché y adaptación de protocolos. Es ideal para bucles cerrados en tiempo real y para minimizar cargas de datos sensibles. La potencia de hash edge suele ser limitada, por lo que se enfatizan compresión de modelos, poda de tareas y latencia determinista.
Capa regional (campo medio)
Proporciona mayor potencia de hash y un stack de servicios más completo dentro de países o regiones geográficas específicas, cubriendo residencia de datos, auditoría de cumplimiento y necesidades de inferencia agregada a escala media. Además, suele servir como plano de agregación y control para múltiples nodos edge.
Capa central (campo lejano)
Gestiona entrenamiento, procesamiento por lotes a gran escala, administración global de modelos, orquestación compleja de agentes, gobernanza unificada entre tenants y optimización de costes. Es adecuada para cargas menos sensibles a la latencia pero que requieren alta potencia de hash y agregación de datos.
Estas tres capas no son jerarquías fijas, sino divisiones por tareas de negocio. Las empresas pueden operar simultáneamente entrenamiento central, inferencia online regional y detección edge en tiempo real, enrutando solicitudes a la capa adecuada según estrategias de routing.
Partición de tareas: qué permanece en edge, qué retorna al centro
Los principios de partición suelen girar en torno a cuatro ejes: minimización de datos, presupuesto de latencia, complejidad de modelos y frecuencia de actualización.
Tareas adecuadas para edge (suponiendo que se cumplen los requisitos de potencia de hash):
-
Extracción de características en tiempo real, detección de objetos, controles de calidad y otros bucles cerrados de baja latencia
-
Inferencia ligera tras desensibilización local (por ejemplo, subir solo vectores de características en vez de medios brutos)
-
Estrategias de inferencia fallback y cache hit en entornos de red débil
Tareas adecuadas para centro o región:
-
Workflows de agentes que requieren gran contexto, modelos potentes, toolchains complejos o orquestación multisistema
-
Inferencia analítica que requiere agregación de datos interdepartamental
-
Llamadas sensibles que requieren auditoría centralizada y gestión unificada de claves
Errores comunes de partición incluyen forzar modelos grandes con contexto largo en edge, resultando en OOM, o enviar bucles cerrados de baja latencia completamente al centro, causando disrupciones en el ritmo de la línea de producción. El objetivo del diseño de topología no es “cuanto más edge, mejor”, sino ubicar la carga adecuada en el lugar correcto bajo restricciones.
Soberanía de datos y cumplimiento: la topología impulsa la arquitectura
Los requisitos de soberanía de datos alteran directamente las formas de despliegue de inferencia. Los modelos pueden descargarse localmente, pero logs, cachés, índices vectoriales y trazas de llamadas aún pueden suponer riesgos de cumplimiento. En la práctica, las preguntas clave incluyen:
-
Qué datos deben almacenarse y computarse en edge o región
-
Qué metadatos pueden salir de la región o ir a la nube, y si se requieren anonimización y periodos de retención
-
Si está permitido el uso cross-region de distintas versiones de modelos y proveedores (para evitar “drift de cumplimiento”)
-
Si durante auditoría y forensics se puede reconstruir la salida como “generada en cierta ubicación, hora y en base a fragmentos de datos específicos”
Las respuestas a estas preguntas suelen determinar si un sistema puede ponerse en marcha, más que “si el modelo es open source”. En otras palabras, el cumplimiento no es un complemento para la inferencia edge, sino una condición de entrada para el diseño de topología.
Red, energía y operaciones: los costes reales del despliegue distribuido
La inferencia distribuida implica costes sistémicos que deben evaluarse explícitamente durante la planificación:
-
Red: A medida que aumentan los nodos edge y regionales, la gestión de certificados, líneas dedicadas / SD‑WAN, DNS y la complejidad de scheduling de tráfico se incrementan. La latencia final es más difícil de gobernar bajo condiciones multipath.
-
Energía y centros de datos: Los sitios edge están dispersos y la eficiencia energética y condiciones de refrigeración por unidad de potencia de hash pueden ser inferiores a las de grandes centros de datos; los centros regionales son intermedios. El ritmo de entrega upstream de energía y racks sigue limitando la velocidad de expansión, pero el límite pasa de “un solo campus” a “multipunto en paralelo”.
-
Operaciones y consistencia de versiones: Cuando modelos, prompts, estrategias de routing e índices se liberan en múltiples puntos, puede ocurrir drift de versiones. Se necesitan pipelines de liberación unificados, estrategias de rollback y health checks, o los costes de troubleshooting erosionarán rápidamente las ganancias de latencia aportadas por edge.
-
Expansión del alcance de seguridad: Más nodos implican más certificados, más puntos de entrada y más medios de almacenamiento local. La seguridad física y los ciclos de parches en edge suelen ser más débiles que en centros centrales, requiriendo estrategias específicas de privilegio mínimo y control remoto.
Por tanto, la topología distribuida no es simplemente “empujar la potencia de hash hacia fuera”, sino trasladar parte de la complejidad operativa y de gobernanza más cerca del sitio de negocio. Si las capacidades organizativas y las herramientas de plataforma no acompañan, las ventajas de topología serán difíciles de materializar.
Relación con la inferencia centralizada: cómo se implementan arquitecturas híbridas
La mayoría de soluciones maduras adoptan arquitecturas híbridas: el centro gestiona entrenamiento, políticas globales y cargas pesadas; la región gestiona servicios online dentro de zonas de cumplimiento; edge gestiona baja latencia y resiliencia local. Los patrones ingenieriles comunes incluyen:
-
Caché por capas y reutilización de resultados: Edge atiende solicitudes de alta frecuencia y los fallos se envían al centro. Se deben definir claves de caché, TTL y políticas de datos sensibles.
-
Split de modelos y modelos pequeños frontales: Edge ejecuta modelos pequeños de detección o clasificación, el centro ejecuta fusión de modelos grandes y generación de interpretación (evaluado por escenario).
-
Retorno asíncrono y agregación: Edge toma decisiones en tiempo real y luego retorna muestras desensibilizadas o métricas para iteración y monitorización de modelos.
-
Plano de control unificado: Routing, cuotas, monitorización y gestión de claves se centralizan tanto como sea posible, con ejecución descentralizada, para reducir el riesgo de “cada edge como isla aislada”.
La clave de arquitecturas híbridas exitosas es plano de control unificado más plano de ejecución por capas—no simplemente aumentar el número de nodos.
Conclusión
La esencia de los debates sobre inferencia edge y distribuida no es un “eslogan de descentralización”, sino decisiones ingenieriles entre latencia, ancho de banda, cumplimiento y coste operativo. A medida que el negocio pasa de demo a escala, las elecciones de topología moldean formas de modelos, arquitecturas de red y procesos organizativos. Ignorar esta capa puede resultar en gran potencia de hash central pero inestabilidad persistente en la línea de frente.









