Article | Sleepy.md
Dans la ville de Datong, dans la province du Shanxi, qui avait autrefois soutenu une large moitié de la prospérité grâce au charbon, la poussière de charbon s’est maintenant déposée sur ses épaules. Avec un pic/une pioche plus tranchant(e), elle s’abat lourdement vers une autre mine invisible.
Dans les bureaux du centre international Jimao, au district de Pingcheng, il n’y a plus de puits élévateur. Il n’y a plus non plus de camions pour transporter le charbon. À leur place, il y a des milliers de postes informatiques étroitement alignés. Le centre de services de données intelligentes de la “zone de la vallée du son” de Runxun Yun (à Shanghai) occupe plusieurs étages entiers. Des milliers de jeunes employés munis d’écouteurs, fixent l’écran, cliquent, font glisser, sélectionnent des cadres.
Selon des données officielles, au 11/2025, la ville de Datong a déjà mis en service 745 000 serveurs, a fait entrer 69 entreprises de données d’appels avec étiquetage et, ce faisant, a permis de générer plus de 30 000 emplois à proximité, avec une valeur de production de 750 millions de yuans. Dans ce gouffre numérique, 94 % des personnes employées ont un registre local (résidence).
Ce n’est pas seulement Datong. Parmi les premiers centres d’étiquetage de données confirmés par l’administration nationale des données, on trouve clairement, au sein des villes et comtés de l’intérieur comme du centre de la Chine : le comté de Yonghe dans le Shanxi, la ville-ressortissante de Bijie dans le Guizhou, Mengzi dans le Yunnan, etc. Dans le centre d’étiquetage de données de Yonghe, 80 % sont des employées. Elles sont pour la plupart des mères au foyer rurales, ou bien des jeunes qui sont rentrés au pays parce qu’elles n’ont pas trouvé de travail approprié.
Il y a cent ans, dans les usines textiles de Manchester en Angleterre, on y voyait entassés des paysans qui avaient perdu leurs terres. Et aujourd’hui, devant des écrans d’ordinateur dans ces comtés reculés, on y trouve des jeunes qui ne trouvent pas de place dans l’économie réelle.
Ils effectuent un travail à la tâche à la fois très futuriste et pourtant extrêmement primaire, produisant les données indispensables à la production de grands modèles pour les géants de l’intelligence artificielle de Pékin, Shenzhen et de la Silicon Valley.
Personne ne pense qu’il y a là le moindre problème.
Nouvelle chaîne de production sur le plateau du Loess
L’essence même de l’étiquetage de données, c’est d’apprendre à la machine à reconnaître le monde.
La conduite autonome doit identifier les feux tricolores et les piétons ; les grands modèles doivent distinguer ce qui est un chat et ce qui est un chien. La machine, elle-même, n’a aucune notion de bon sens : il faut d’abord, par des humains, dessiner un cadre sur l’image, lui dire « voici un piéton », puis seulement après avoir “ingéré” des dizaines de millions d’images, elle apprend à reconnaître par elle-même.
Ce travail ne demande pas un haut niveau d’études : il faut juste de la patience, et un doigt capable de cliquer sans arrêt.
À l’âge d’or de 2017, un simple cadre 2D coûtait plus d’un mao ; certains ont même proposé un prix de 5 mao. Les étiqueteurs, au temps de travail élevé et à la main rapide, pouvaient travailler des dizaines d’heures par jour et gagner ainsi 5 à 6 cents yuans. Dans un comté, c’est assurément un emploi très bien payé et décent.
Mais avec l’évolution des grands modèles, la face cruelle de cette chaîne de production a commencé à se révéler.
En 2023, le prix unitaire de l’étiquetage simple d’images a déjà été ramené à 3 à 4 fen. La baisse dépasse 90 %. Même pour les nuages de points 3D plus difficiles, ces images composées d’une multitude de points, qu’il faut agrandir d’infinies fois pour voir les bords : l’étiqueteur doit aussi, dans l’espace tridimensionnel, tracer un cadre en volume incluant longueur, largeur, hauteur et angle de déviation, afin d’envelopper au millimètre près le véhicule ou le piéton. Et un cadre 3D aussi complexe ne vaut pourtant que 5 fen.
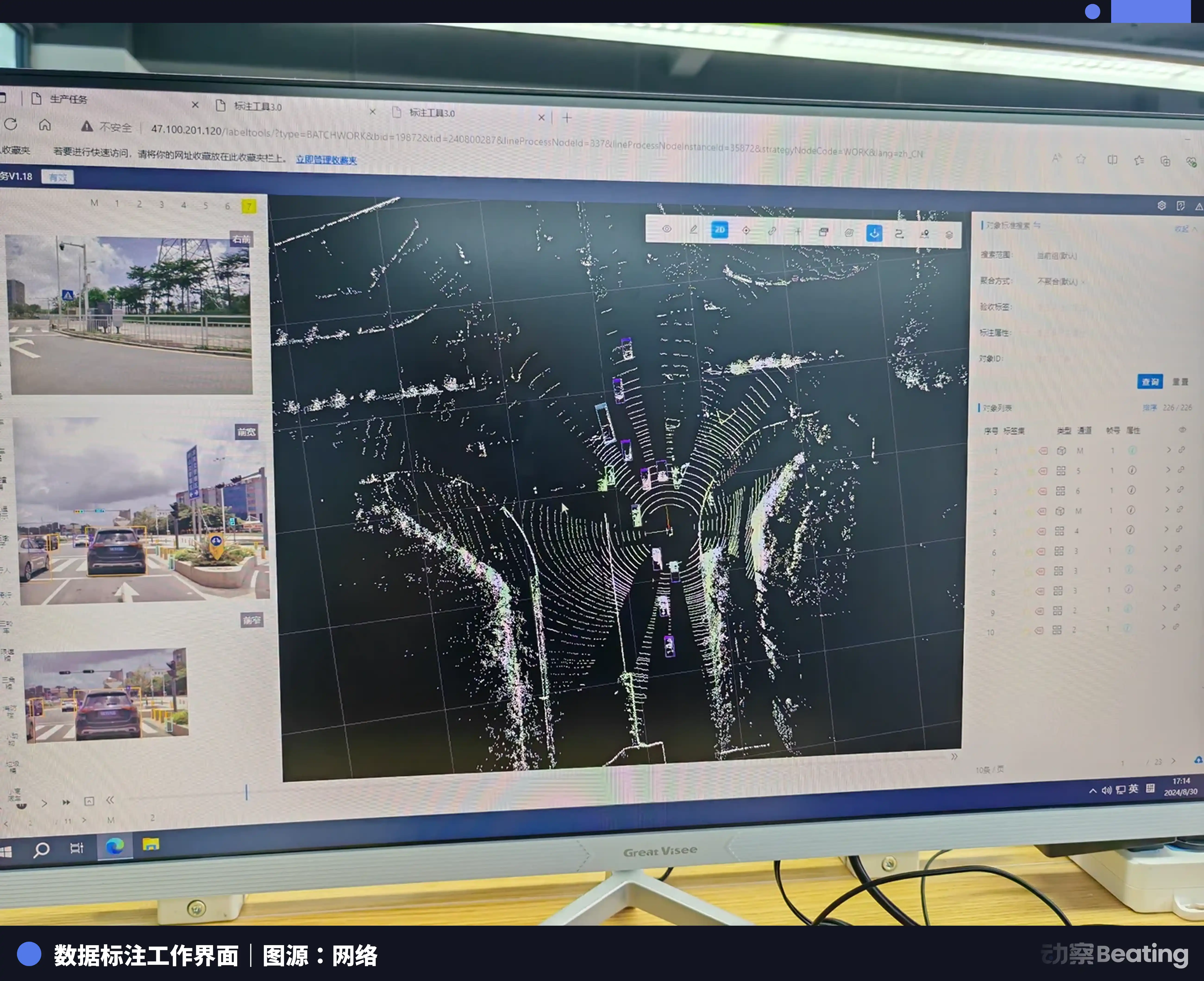
La conséquence directe de l’effondrement du prix unitaire, c’est l’explosion de l’intensité du travail. Pour continuer à mordre fermement sur le salaire de base de 2 000 à 3 000 yuans par mois, les étiqueteurs doivent sans cesse, sans arrêt, améliorer la vitesse de leurs gestes.
Ce n’est absolument pas un travail de bureau facile. Dans beaucoup de centres d’étiquetage, la gestion est si stricte qu’elle en devient suffocante : au travail, il est interdit de prendre des appels ; le téléphone doit être verrouillé dans un casier. Le système enregistre avec précision la trajectoire de la souris de chaque employé et le temps de stationnement. Si l’on s’arrête plus de trois minutes, les avertissements en coulisses arrivent comme des coups de fouet.
Ce qui rend surtout les gens désespérés, c’est le taux de tolérance aux erreurs. La note minimum de l’industrie se situe souvent au-dessus de 95 %, et certaines entreprises exigent même 98 %-99 %. Cela signifie qu’en traçant 100 cadres, tant que vous vous trompez sur 2 d’entre eux, toute l’image est renvoyée pour correction.
Les images en mouvement sont enchaînées : lors d’un changement de voie, le véhicule peut être masqué, et l’étiqueteur doit alors les retrouver un par un par déduction ; dans les nuages de points 3D, dès qu’un objet dépasse 10 points, il faut dessiner un cadre. Sur un projet de place de stationnement complexe, si la ligne est trop longue ou si des étiquettes sont oubliées, lors de l’inspection qualité, on finira toujours par trouver des défauts. Corriger une image quatre ou cinq fois est chose courante. Au final, après calcul, avec une heure de travail, il reste seulement quelques mao/fen.
Un étiqueteur dans le Hunan a publié sur une plateforme sociale sa fiche de règlement : après une journée de travail, elle a tracé plus de 700 cadres, avec un prix unitaire de 4 fen, pour un revenu total de 30,2 yuans.
C’est une image extrêmement clivée.
D’un côté, les grands pontes de la tech, brillants et resplendissants lors des conférences, parlent de la façon dont l’AGI libérera l’humanité ; de l’autre, dans des comtés du plateau du Loess et dans les montagnes du sud-ouest, des jeunes passent chaque jour 8 à 10 heures les yeux rivés sur l’écran, traçant machinalement des cadres, des milliers, des dizaines de milliers, et même la nuit en rêvant, les doigts, dans l’air, dessinent des lignes de voie.
Quelqu’un a déjà dit : l’apparence de l’intelligence artificielle, c’est une voiture de luxe qui fonce à toute allure, mais quand vous ouvrez la portière, vous découvrez qu’à l’intérieur, il y a cent personnes en train de pédaler à vélo, en serrant les dents, en appuyant de toutes leurs forces sur les pédales.
Personne ne pense qu’il y a là le moindre problème.
Le travail à la tâche pour apprendre à la machine « comment aimer »
Une fois que le goulot d’étranglement de la reconnaissance d’images a été percé, les grands modèles ont fait un bond vers une évolution plus profonde : il leur faut apprendre à penser, dialoguer, comme des humains, et même à faire preuve de « sensibilité empathique ».
Cela donne naissance à l’étape la plus centrale et aussi la plus coûteuse de l’entraînement des grands modèles : RLHF (apprentissage par renforcement à partir de retours humains).
En termes simples : on fait noter par des personnes réelles les réponses générées par l’IA, et on lui indique quelle réponse est meilleure, et qui correspond le plus aux valeurs et préférences émotionnelles humaines.
Si ChatGPT a l’air de « ressembler à un humain », c’est parce qu’en coulisses, il y a d’innombrables étiqueteurs RLHF qui lui donnent des cours.
Sur des plateformes de crowdourcing, ce type de tâche d’étiquetage est souvent tarifé explicitement : coût par pièce de 3 à 7 yuans. Les étiqueteurs doivent attribuer une note émotionnelle extrêmement subjective aux réponses de l’IA, afin de juger si cette réponse est « chaleureuse », si elle « fait preuve d’empathie », si elle « prend en compte les émotions de l’utilisateur ».
Une personne payée un salaire mensuel de 2 000 à 3 000 yuans, qui peine et court dans la boue du quotidien, au point même de ne pas avoir le temps de s’occuper de ses propres émotions, se retrouve pourtant dans le système comme mentor émotionnel de l’IA et arbitre des valeurs.
Ils doivent prendre des émotions humaines extrêmement complexes et subtiles — la chaleur, l’empathie — et les réduire de force en morceaux, puis les quantifier en scores froids de 1 à 5. Si leurs notes ne correspondent pas aux “bonnes réponses” définies par le système, ils sont alors jugés “taux de justesse insuffisant”, et voient ainsi déduits des revenus déjà très maigres.
C’est une forme d’extraction de la cognition. Les émotions complexes, fines, la morale et la compassion de l’humain, sont arrachées de force et entraînées dans un entonnoir d’algorithmes. Dans les échelles froides de quantification et de standardisation, elles sont pressées jusqu’à en extraire la dernière chaleur. Lorsque vous vous émerveillez du fait que le monstre cybernétique de l’écran a appris à écrire des poèmes, à composer des partitions, à prendre des nouvelles et à faire preuve de sollicitude, et même à revêtir une peau pleine de sensibilité ; mais quand vous regardez de l’autre côté de l’écran, ces humains vivants qui étaient autrefois là reculent, eux, dans une série de jugements mécaniques jour après jour, jusqu’à se dégrader en machines à attribuer des notes sans émotion.
C’est la face la plus secrète de toute la chaîne industrielle : elle n’apparaît jamais dans des actualités de financement ni dans des livres blancs techniques.
Personne ne pense qu’il y a là le moindre problème.
Masters 985 et jeunes des villes de province
Le travail de tracement à la base est en train d’être broyé par les chenilles de l’IA. Cette chaîne de production cyber s’étend vers le haut et commence à engloutir des tâches cognitives de niveau supérieur.
L’appétit des grands modèles a changé. Ils ne se contentent plus de mâcher et broyer des connaissances élémentaires et du “bon sens” simple : ils doivent engloutir les connaissances professionnelles humaines et une logique de plus haut niveau.
Sur les grandes plateformes de recrutement, des offres de temps partiel spéciales commencent à clignoter fréquemment, comme « étiquetage d’inférence logique pour grands modèles » ou « formateur en humanités pour l’IA ». Le seuil de ces jobs est très élevé : on exige souvent « diplôme master 985/211 ou supérieur », et cela concerne des domaines spécialisés tels que le droit, la médecine, la philosophie, la littérature, etc.
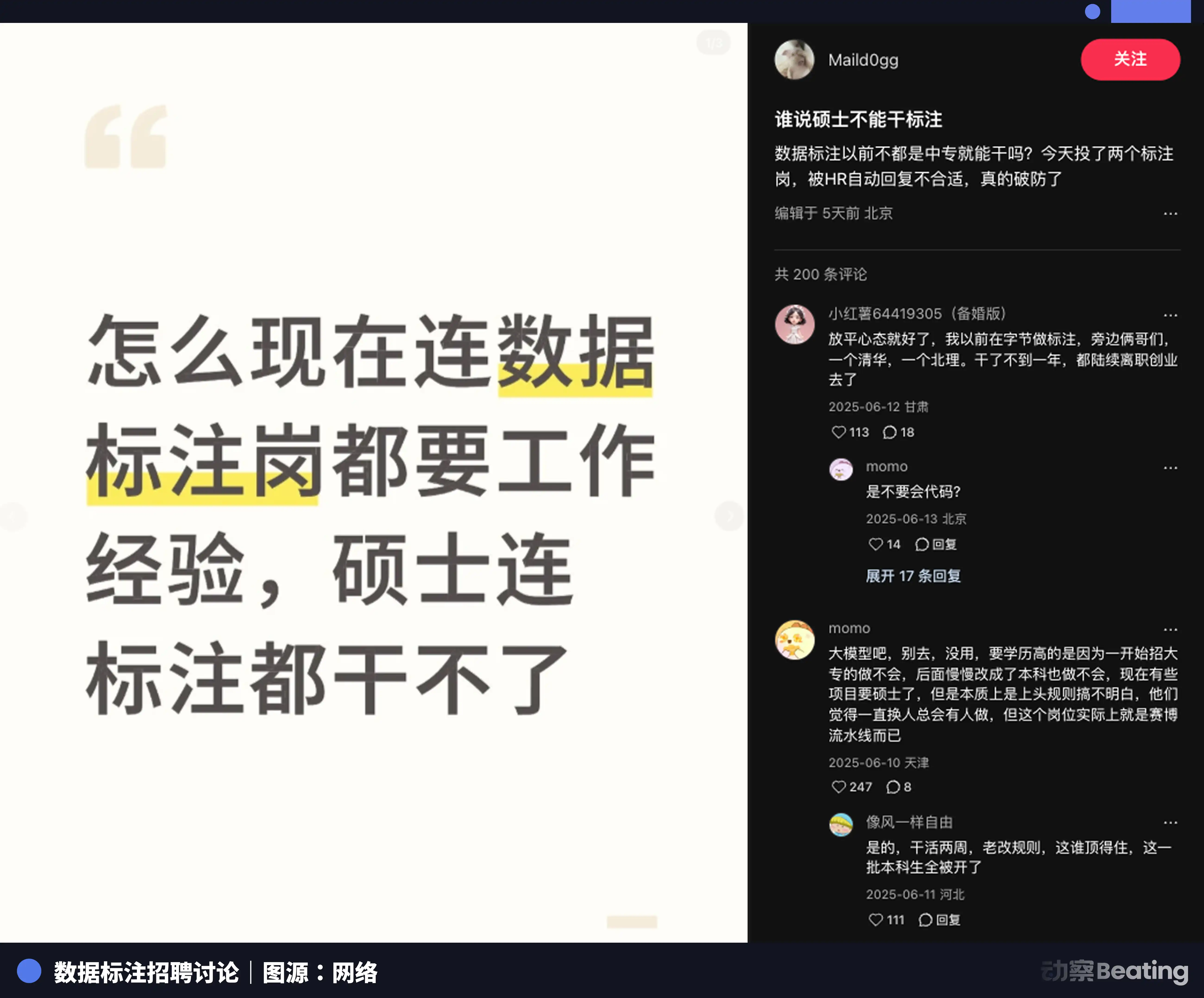
De nombreux étudiants diplômés d’écoles prestigieuses sont attirés et affluent dans les groupes de sous-traitance de ces grandes entreprises. Mais très vite, ils découvrent que ce n’est pas du tout un entraînement cognitif facile : c’est une torture psychologique.
Avant de recevoir une commande officielle, ils doivent lire des documents de dizaines de pages sur les dimensions de notation et les critères d’évaluation, et passer deux à trois tours de test d’étiquetage. Après avoir passé, dans l’étiquetage officiel, si le taux de justesse est inférieur à la moyenne, ils perdent leur éligibilité et se font exclure du groupe.
Ce qui étouffe le plus, c’est que ces critères ne sont même pas fixes. Face à des questions et des réponses similaires, noter avec le même mode de pensée peut aboutir à des résultats totalement opposés. C’est comme devoir faire un examen qui ne finit jamais et qui n’a tout simplement pas de corrigé standard. Impossible d’améliorer le taux de justesse par des efforts personnels ou par l’apprentissage : on ne peut que tourner sur place, consommer sans arrêt des ressources mentales et physiques.
Voilà donc la nouvelle exploitation à l’ère des grands modèles : l’effondrement des classes.
Le savoir, autrefois considéré comme une marche d’or permettant de briser des barrières et de grimper vers le haut, est maintenant réduit à un pâturage numérique offert en hommage aux algorithmes — un “fourrage” encore plus complexe à mâcher. Devant le pouvoir absolu des algorithmes et des systèmes, le master 985 dans une tour d’ivoire et le jeune des villes du plateau du Loess dans un comté se retrouvent dans une destinée bizarrement identique.
Ensemble, ils chutent dans cette fosse cyber au fond impossible à voir, perdent leurs insignes, gommant les différences, devenant tous des engrenages bon marché sur les chenilles, remplaçables à tout moment.
C’est pareil à l’étranger. En 2024, Apple a supprimé directement un groupe d’étiquetage vocal de l’IA de 121 personnes à Santiago. Ces employés étaient chargés d’améliorer la capacité de Siri à gérer plusieurs langues. Ils pensaient auparavant être en périphérie de l’activité cœur d’une grande entreprise, mais ils sont immédiatement tombés dans l’abîme du chômage.
Aux yeux des géants de la tech, qu’il s’agisse de la femme qui trace des cadres dans un comté ou du formateur en logique diplômé d’une école prestigieuse, ils ne sont en essence que des « consommables » remplaçables à tout moment.
Personne ne pense qu’il y a là le moindre problème.
Un Babel de mille milliards, des sueurs de sang pour quelques centimes
D’après les données publiées par le China Academy of Information and Communications Technology, la taille du marché chinois de l’étiquetage de données en 2023 atteint 60,8 milliards de yuans ; en 2025, elle devrait atteindre 200 à 300 milliards de yuans. Selon les prévisions, d’ici 2030, les ventes mondiales des marchés de l’étiquetage et des services de données bondiront jusqu’à 117,1 milliards de yuans.
Derrière ces chiffres, il y a une fête des valorisations — des milliers de milliards, voire des dizaines de milliers de milliards de dollars — de géants technologiques comme OpenAI, Microsoft, ByteDance, etc.
Mais cette fortune ruisselante n’est pas allée à ceux qui « nourrissent » réellement l’IA.
L’industrie chinoise de l’étiquetage de données présente une structure typique d’externalisation à l’envers en forme de pyramide. Au sommet, ce sont les géants tech qui tiennent fermement les algorithmes centraux ; à la deuxième couche, les grands fournisseurs de services de données ; à la troisième, les centres d’étiquetage de données répartis partout et les petites et moyennes entreprises d’externalisation ; et tout en bas, ce sont les étiqueteurs de “petits bras” payés à la tâche.
À chaque couche d’externalisation, on gratte brutalement une couche de marges. Lorsque le prix unitaire “lancé” par les grandes entreprises est de 5 mao, après avoir été dépouillé couche après couche, ce qui finit entre les mains des étiqueteurs de comté peut être à peine inférieur à 5 fen.
L’ancien ministre grec des Finances Yanis Varoufakis, dans son ouvrage « Le féodalisme technologique », a avancé un point de vue très percutant : aujourd’hui, les géants technologiques ne sont plus des capitalistes au sens traditionnel, mais des « seigneurs du cloud » (Cloudalists).
Ils ne possèdent pas des usines ni des machines, mais des algorithmes, des plateformes, et de la puissance de calcul : ce sont des territoires numériques à l’ère cyber. Dans ce nouveau système féodal, les utilisateurs ne sont pas des consommateurs, mais des fermiers numériques. Chaque like, chaque commentaire, chaque consultation sur les réseaux sociaux que nous faisons sert gratuitement les données aux seigneurs du cloud.
Et les étiqueteurs de données qui se trouvent dans les marchés “descendants” sont, dans ce système, les esclaves numériques les plus à la base. Ils doivent non seulement produire des données, mais aussi nettoyer, classifier et noter d’énormes volumes de données brutes, pour les transformer en aliments de haute qualité que les grands modèles peuvent digérer.
C’est un mouvement discret de “prise de terres” cognitives. Comme, au XIXe siècle, le mouvement des enclosures en Angleterre a chassé les paysans vers les usines textiles, aujourd’hui la vague d’IA a poussé les jeunes qui ne trouvent pas de place dans l’économie réelle à se retrouver devant des écrans.
L’IA ne supprime pas les écarts de classe ; elle établit plutôt une « bande transporteuse de données et de sueur » allant des comtés de l’intérieur et du centre de la Chine jusqu’au siège des géants tech de Pékin, Tianjin, Shanghai, Guangzhou, Shenzhen. Le récit des révolutions technologiques est toujours grandiose et éclatant, mais la couleur de fond, elle, est toujours la consommation à grande échelle d’une main-d’œuvre bon marché.
Personne ne pense qu’il y a là le moindre problème.
Ne plus avoir besoin du lendemain des humains
La conclusion la plus cruelle approche, et de plus en plus vite.
À mesure que les capacités des grands modèles progressent, ces tâches d’étiquetage qui nécessitaient auparavant le travail nuit et jour des humains sont en train d’être reprises par l’IA elle-même.
En avril 2023, le fondateur de Li Auto, Li Xiang, a révélé des données sur un forum : auparavant, Li Auto devait faire manuellement l’étalonnage/étiquetage de l’image de conduite autonome d’environ 10 millions de frames par an. Le coût d’externalisation était proche d’un milliard. Mais lorsqu’ils ont utilisé des grands modèles pour automatiser l’étiquetage, ce qui nécessitait auparavant une année de travail peut désormais être fait en base à peu près 3 heures.
L’efficacité est 1000 fois celle des humains — et en plus, dès 2023. Au cours du mois de mars qui vient tout juste de se terminer, Li Auto a également publié le nouvel moteur d’étiquetage automatique MindVLA-o1 de nouvelle génération.
Dans l’industrie, on entend une boutade d’autodérision extrêmement vraie : « s’il y a combien d’intelligence, il y aura autant de travail humain ». Mais désormais, les investissements des grandes entreprises dans l’externalisation de l’étiquetage de données ont déjà chuté de façon abrupte de 40 %-50 %.
Ces jeunes des petites villes qui sont restés des nuits entières devant des écrans, à faire brûler leurs yeux, ont de leurs propres mains nourri un monstre géant. Et maintenant, ce monstre se retourne : il casse leur gagne-pain.
À la tombée de la nuit, les immeubles de bureaux du district de Pingcheng à Datong restent aussi blancs que le jour. Dans les couloirs d’échange des équipes, les jeunes en rotation se remplacent silencieusement, en échangeant leurs corps fatigués. Dans cet espace de repli verrouillé par d’innombrables cadres de polygones, personne ne se soucie de savoir quelle autre montée épique la structure Transformer de l’autre côté de l’océan vient encore de vivre ; et personne n’arrive à comprendre le grondement de la puissance de calcul derrière des centaines de milliards de paramètres.
Leur regard n’est fixé que sur cette barre d’avancement rouge-vert qui représente « la ligne de passage » en arrière-plan, calculant si ces quelques points, ces quelques mao de données à la tâche permettront d’assembler une vie décente à la fin du mois.
D’un côté, il y a le carillon de la cloche du Nasdaq et les torrents de textes des médias tech, tandis que les géants trinquent à l’avènement de l’AGI ; de l’autre, ces fermiers numériques, qui ont grandi l’IA à coup de bouchées de chair et de sang, ne peuvent que trembler dans des rêves douloureux, attendant avec frayeur que le monstre — qu’ils ont eux-mêmes nourri —, lors d’un matin qui semble tout à fait ordinaire, d’un geste tranquille leur donne un coup de pied et casse leur gagne-pain.
Personne ne pense qu’il y a là le moindre problème.
Cliquez pour découvrir les postes — BlockBeats — en recrutement
Bienvenue à rejoindre la communauté officielle de BlockBeats :
Groupe de souscription Telegram : https://t.me/theblockbeats
Groupe Telegram : https://t.me/BlockBeats_App
Compte officiel Twitter : https://twitter.com/BlockBeatsAsia
