Seiring workload inferensi berkembang dari klaster uji menuju aplikasi bisnis nyata, solusi optimal default tidak selalu berupa "semua terpusat di pusat data skala ultra besar." Artikel ini membahas logika berlapis dari node edge, pusat data regional, dan klaster pusat berdasarkan latensi, bandwidth, ketersediaan, dan kepatuhan. Artikel ini menjelaskan poin utama dalam pembagian tugas, batas data, serta tata kelola operasional dalam topologi hybrid, dan memberikan gambaran perbandingan terhadap rantai infrastruktur AI yang lebih luas.
Narasi publik kerap menyamakan hash power AI dengan "pusat data skala ultra besar plus GPU kelas atas." Untuk pelatihan dan beberapa skenario inferensi terpusat, definisi ini umumnya relevan. AI Infrastructure memiliki permintaan inferensi yang tersebar luas, sangat sensitif terhadap latensi, dan mewajibkan data tetap berada dalam domain, sementara gangguan jaringan atau kemacetan puncak tidak dapat diterima. Dalam kasus seperti ini, topologi inferensi menjadi isu infrastruktur: hash power tidak hanya harus tersedia, tetapi juga berada di "posisi geografis yang tepat dan lapisan jaringan yang tepat."
Jika infrastruktur AI dipandang sebagai rantai berkesinambungan, mulai dari level chip hingga layanan dan tata kelola, artikel ini berfokus pada topologi dan bentuk deployment: bagaimana mengalokasikan komputasi dan data di antara lapisan edge, regional, dan pusat untuk menyeimbangkan latensi, biaya, ketersediaan, dan kepatuhan. Topik upstream seperti listrik, packaging, dan HBM lebih cocok untuk diskusi sisi pasokan, sementara detail routing multi-model tingkat enterprise dan tata kelola agen melengkapi operasi produksi.
Mengapa Membahas "Topologi Inferensi Terdistribusi"
Inferensi terpusat menawarkan operasi terpadu, skalabilitas fleksibel, dan pemanfaatan sumber daya tinggi. Namun, ketika bisnis memiliki karakteristik berikut, keputusan topologi sangat memengaruhi pengalaman dan biaya:
- Kendala latensi yang kuat: Kontrol industri, interaksi real-time, tautan audio/video, dan lokasi ritel offline sangat sensitif terhadap tail latency; jalur return yang terlalu panjang memperbesar jitter.
- Kedaulatan dan residensi data: Skenario seperti informasi pribadi, transaksi keuangan, layanan pemerintah, dan kesehatan sering mengharuskan data tetap berada dalam domain, batas negara, atau wilayah tertentu.
- Bandwidth return dan biaya: Endpoint masif terus mengunggah data mentah ke inferensi pusat, sehingga biaya backbone network dan egress berpotensi menjadi pendorong utama biaya.
- Ketersediaan dan resiliensi: Dalam kasus kegagalan jaringan area luas, fluktuasi DNS, atau kemacetan lintas wilayah, arsitektur yang sepenuhnya terpusat lebih rentan terhadap risiko berantai "ketidaktersediaan seluruh situs."
- Offline atau jaringan lemah: Lingkungan seperti tambang, kapal, dan beberapa lokasi manufaktur memerlukan kemampuan operasi lokal, bukan ketergantungan kuat pada konektivitas online real-time.
Tantangan ini tidak dapat diselesaikan hanya dengan "model pusat yang lebih kuat," karena inti masalahnya terletak pada jarak fisik, jalur jaringan, dan batas kebijakan—bukan pada puncak hash power dari satu inferensi.
Deployment Berlapis: Solusi Edge, Regional, dan Central Layer
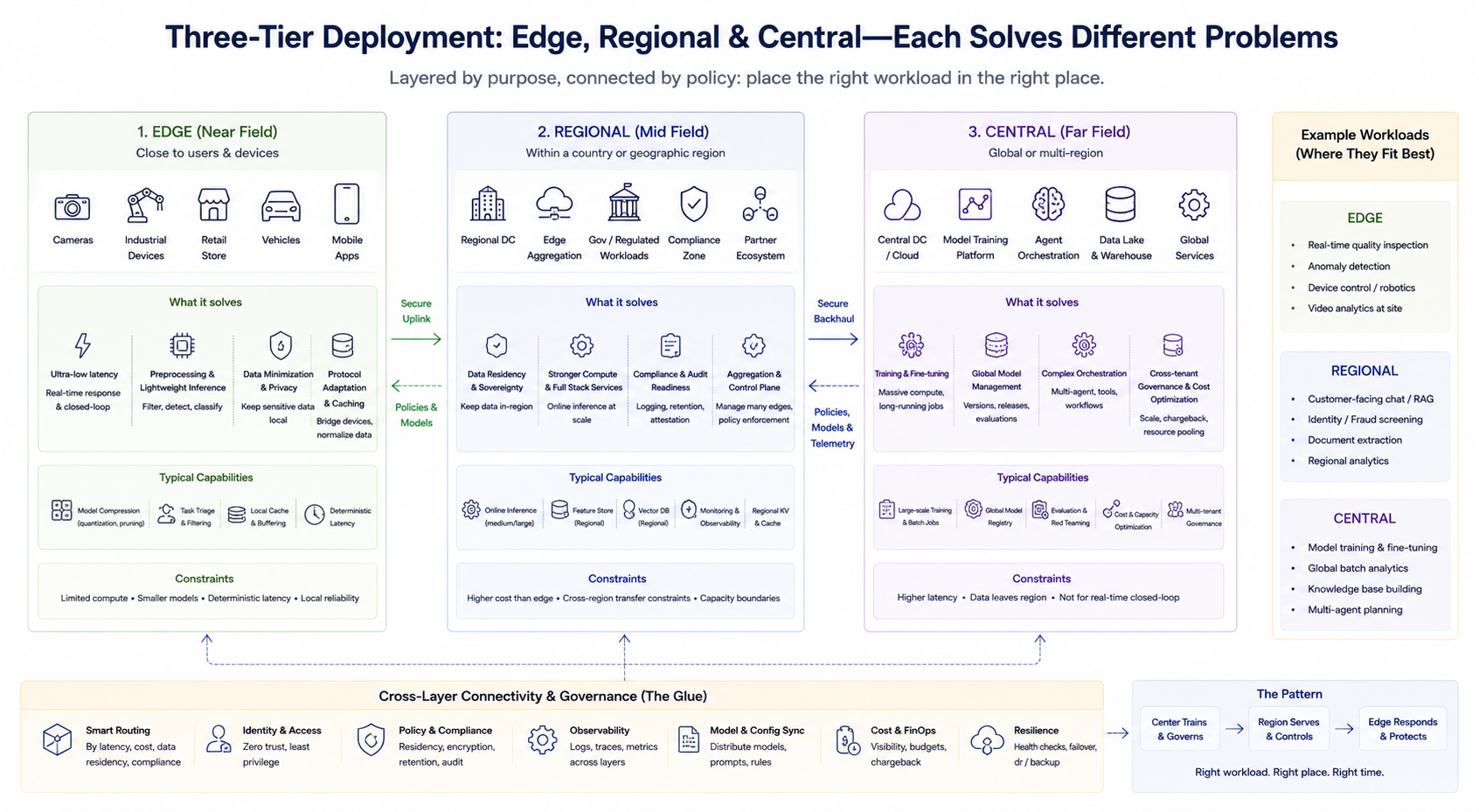
Pendekatan rekayasa yang umum bukanlah pilihan biner, melainkan kombinasi berlapis. Kerangka kerja sederhana membantu memperjelas tanggung jawab tiap lapisan (penamaan spesifik dapat berbeda tergantung penyedia):
Lapisan Edge (Near Field)
Berada dekat dengan pengguna atau perangkat, lapisan ini menangani pra-pemrosesan latensi rendah, inferensi ringan, caching, dan adaptasi protokol. Cocok untuk closed loop real-time dan meminimalkan upload data sensitif. Hash power edge biasanya terbatas, sehingga kompresi model, pruning tugas, dan latensi deterministik menjadi fokus.
Lapisan Regional (Mid Field)
Menyediakan hash power lebih kuat dan stack layanan lebih lengkap dalam negara atau wilayah geografis tertentu, memenuhi kebutuhan residensi data, audit kepatuhan, dan inferensi agregasi skala menengah. Sering juga berfungsi sebagai plane agregasi dan kontrol untuk beberapa node edge.
Lapisan Central (Far Field)
Menangani pelatihan, pemrosesan batch skala besar, manajemen model global, orkestrasi agen kompleks, tata kelola cross-tenant terpadu, dan optimasi biaya. Cocok untuk workload yang kurang sensitif terhadap latensi tetapi membutuhkan hash power tinggi dan agregasi data.
Ketiga lapisan ini bukanlah hierarki tetap, melainkan dibedakan berdasarkan tugas bisnis. Perusahaan dapat secara bersamaan menjalankan pelatihan pusat, inferensi online regional, dan deteksi real-time edge, mengarahkan permintaan ke lapisan yang sesuai menurut strategi routing.
Pembagian Tugas: Apa yang Tetap di Edge, Apa yang Kembali ke Center
Prinsip pembagian biasanya berputar pada empat sumbu: minimisasi data, anggaran latensi, kompleksitas model, dan frekuensi update.
Tugas yang cocok untuk edge (asalkan kebutuhan hash power terpenuhi):
- Ekstraksi fitur real-time, deteksi objek, pemeriksaan kualitas, dan closed loop latensi rendah lainnya
- Inferensi ringan setelah desensitisasi lokal (misal, hanya mengunggah feature vector, bukan media mentah)
- Strategi fallback inferensi dan cache hit di lingkungan jaringan lemah
Tugas yang cocok untuk center atau regional:
- Workflow agen yang membutuhkan konteks besar, model kuat, toolchain kompleks, atau orkestrasi multi-sistem
- Inferensi analitik yang memerlukan agregasi data lintas departemen
- Panggilan sensitif yang membutuhkan audit terpusat dan manajemen kunci terpadu
Kesalahan umum dalam pembagian adalah memaksakan model besar dengan konteks panjang ke edge, sehingga terjadi OOM, atau mengirim closed loop yang membutuhkan latensi rendah seluruhnya ke center, menyebabkan gangguan ritme produksi. Tujuan desain topologi bukanlah "semakin banyak edge semakin baik," melainkan menempatkan workload yang tepat di lokasi yang tepat sesuai batasan.
Kedaulatan Data dan Kepatuhan: Topologi Menggerakkan Arsitektur
Persyaratan kedaulatan data secara langsung mengubah bentuk deployment inferensi. Model dapat diunduh secara lokal, tetapi log, cache, indeks vektor, dan jejak panggilan masih dapat menimbulkan risiko kepatuhan. Dalam praktiknya, pertanyaan kunci meliputi:
- Data mana yang harus disimpan dan dihitung di edge atau regional layer
- Metadata mana yang boleh keluar wilayah atau ke cloud, dan apakah diperlukan anonimisasi serta periode retensi
- Apakah penggunaan lintas wilayah dari versi model dan vendor berbeda diperbolehkan (untuk menghindari "compliance drift")
- Apakah saat audit dan forensik, output dapat direkonstruksi sebagai "dihasilkan di lokasi, waktu, dan berdasarkan fragmen data tertentu"
Jawaban atas pertanyaan-pertanyaan ini sering menentukan apakah sistem dapat go live, lebih daripada "apakah model open source." Dengan kata lain, kepatuhan bukan add-on untuk inferensi edge, melainkan kondisi input untuk desain topologi.
Jaringan, Daya, dan Operasi: Biaya Nyata dari Deployment Terdistribusi
Inferensi terdistribusi membawa biaya sistemik yang harus dievaluasi secara eksplisit saat perencanaan:
- Jaringan: Seiring node edge dan regional bertambah, manajemen sertifikat, dedicated line / SD‑WAN, DNS, dan kompleksitas penjadwalan traffic meningkat. Tail latency lebih sulit dikendalikan di kondisi multipath.
- Daya dan Pusat Data: Situs edge tersebar, dan efisiensi energi serta kondisi pendinginan per unit hash power mungkin lebih lemah dibanding pusat data besar; pusat data regional bersifat intermediate. Kecepatan pengiriman daya dan rack upstream tetap membatasi laju ekspansi, tetapi batasannya bergeser dari "single campus" ke "multi-point parallel."
- Operasi dan Konsistensi Versi: Saat model, prompt, strategi routing, dan indeks dirilis di banyak titik, drift versi dapat terjadi. Pipeline rilis terpadu, strategi rollback, dan health check diperlukan, atau biaya troubleshooting akan segera menggerus keuntungan latensi yang dibawa edge.
- Perluasan Scope Keamanan: Semakin banyak node berarti semakin banyak sertifikat, entry point, dan media penyimpanan lokal. Keamanan fisik dan siklus patch di edge sering lebih lemah dibanding pusat data pusat, sehingga diperlukan strategi minimum privilege dan kontrol jarak jauh yang terarah.
Oleh karena itu, topologi terdistribusi bukan sekadar "mendorong hash power lebih jauh," tetapi memindahkan sebagian kompleksitas operasi dan tata kelola lebih dekat ke lokasi bisnis. Jika kemampuan organisasi dan alat platform tidak ikut berkembang, keunggulan topologi sulit direalisasikan.
Hubungan dengan Inferensi Terpusat: Implementasi Arsitektur Hybrid
Sebagian besar solusi matang mengadopsi arsitektur hybrid: pusat menangani pelatihan, kebijakan global, dan workload berat; regional menangani layanan online dalam zona kepatuhan; edge menangani latensi rendah dan resiliensi lokal. Pola rekayasa umum meliputi:
- Caching berlapis dan reuse hasil: Edge melayani permintaan berfrekuensi tinggi, miss dikirim ke center. Cache key, TTL, dan kebijakan data sensitif harus didefinisikan.
- Pemisahan model dan fronting model kecil: Edge menjalankan model deteksi atau klasifikasi kecil, center menjalankan fusi model besar dan interpretasi (dievaluasi per skenario).
- Return dan agregasi asinkron: Edge mengambil keputusan real-time, lalu mengembalikan sampel atau metrik yang telah didesensitisasi secara asinkron untuk iterasi dan monitoring model.
- Plane kontrol terpadu: Routing, kuota, monitoring, dan manajemen kunci disentralisasi sebisa mungkin, dengan eksekusi terdesentralisasi, untuk mengurangi risiko "setiap edge jadi pulau terisolasi."
Kunci keberhasilan arsitektur hybrid adalah plane kontrol terpadu plus plane eksekusi berlapis—bukan sekadar menambah jumlah node.
Kesimpulan
Inti diskusi edge dan inferensi terdistribusi bukanlah "slogan desentralisasi," melainkan trade-off rekayasa antara latensi, bandwidth, kepatuhan, dan biaya operasi. Saat bisnis beralih dari demo ke skala, pilihan topologi membentuk bentuk model, arsitektur jaringan, dan proses organisasi. Mengabaikan lapisan ini dapat menghasilkan hash power pusat yang kuat tetapi ketidakstabilan terus-menerus di garis depan.








