Mira Dzhobova VikijiはAIで「満点プロジェクト」を作ったの?開発者が実測:本当に中身があるのか、それとも誇大な宣伝・煽りなのか?

ミラ・ジョヴォヴィッチが開発に参加したAIメモリーシステム「MemPalace」は、テストで満点を取り一躍話題になったものの、コミュニティからテスト不正の疑いとデータのミスリードを暴かれてしまいました。実測では効果が誇大で、しかも大量の誤りが見つかり、チームは欠陥を認めて修復に取り組んでいます。
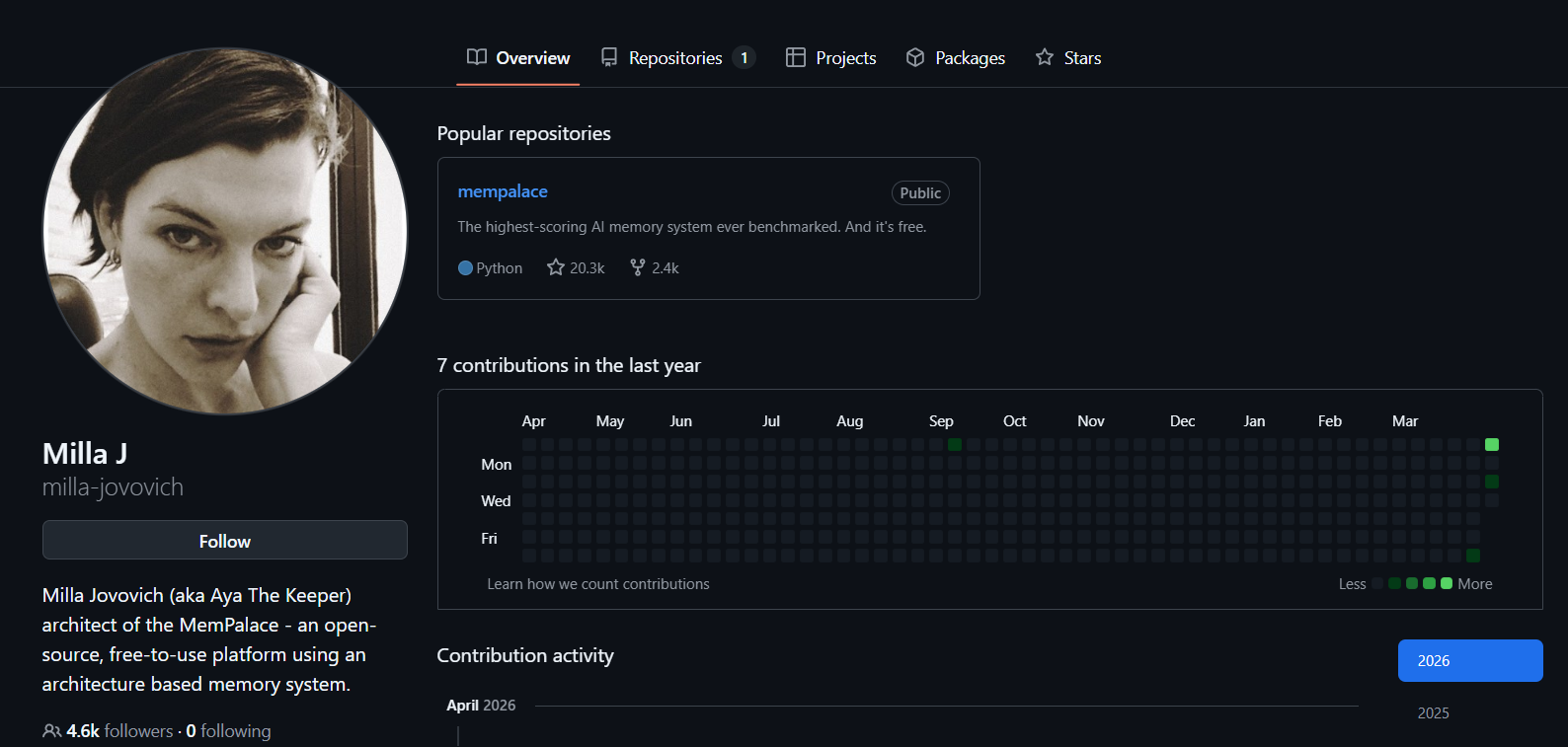
ミラ・ジョヴォヴィッチがAIメモリー宮殿を制作し、外部の注目を集める
昨日(4/7)AI界隈で大きなニュースがありました。『バイオハザード』や『第5元素』で知られるハリウッド女優のミラ・ジョヴォヴィッチ(Milla Jovovich)が、開発者のBen SigmanとともにClaude Codeの支援で「MemPalace」というオープンソースのAIメモリーシステムを開発した、というものです。
一時は、「ハリウッドのスターが他分野から参入し満点のプロジェクトを作った」という話が広まりました。MemPalaceは現時点でもGitHubで2万スター以上を獲得していますが、すぐに開発者コミュニティから疑問が投げかけられました。本当に実力があるのか、それとも誇大宣伝なのか?
まずMemPalaceが生まれた動機を説明しましょう。公式ドキュメントによれば、現在のAIシステムでは、ユーザーとAIの会話内容、意思決定の過程、そしてアーキテクチャに関する議論が、作業セッションの終了後に消えてしまい、数か月の努力がゼロになってしまう制約を解決したいとのことです。
この問題に対処するため、MemPalaceは空間構造を用いてメモリーを保存し、情報を人物やプロジェクトを表す翼区画(ウィングエリア)と、廊下、部屋、引き出しなどの異なる階層の構造に明確に分類します。さらに、後続の意味検索のために会話の原文を保持します。
開発チームは、MemPalaceが長期メモリー評価のベンチマークLongMemEvalで100%の完璧な成績を得たうえで、外部APIを一切呼び出さない状態で96.6%の正確性に到達したと主張しています。しかも完全にローカル端末で動作でき、クラウドサービスのサブスクリプションは不要で、さらに「最大30倍のロスレス圧縮」をうたうAAAK方言システムを搭載しているとのことです。
画像出典:GitHub ミラ・ジョヴォヴィッチがAIメモリー宮殿を制作し、外部の注目を集める
同業者やコミュニティが一斉に疑問視、テスト方法と宣伝に不備
しかし、LongMemEvalで満点という成績は、すぐに同業者からの疑念を呼びました。
同じくAIメモリーシステムを制作しているPenfieldLabsは、MemPalaceがLoCoMoデータセットで満点を取ったと主張しているが、数学的には起こり得ないと指摘します。なぜなら、このデータセットの模範解答自体に99個の誤りが含まれているからです。
PenfieldLabsの分析によると、MemPalaceの100%の成績は、検索回数を50回に設定したことによって生まれていました。しかしテストデータセットの会話の最大段階数は32回しかありません。つまりシステムは検索段階をそのまま素通りして、すべてのデータをAIモデルに読み込ませていることになります。
LongMemEvalでの100%の成績については、開発チームが開発集中で出た3つの特定の問題に対して、専用の修復コードを書いており、テストセットでの不正(チート)を行った疑いがあることが発見されました。

画像出典:Reddit 同業者PenfieldLabsが、MemPalaceはLoCoMoデータセットで満点を取ったと主張しているが、数学的には起こり得ないと指摘
GitHubユーザーの実測で判明、ベンチマークにミスリード要素
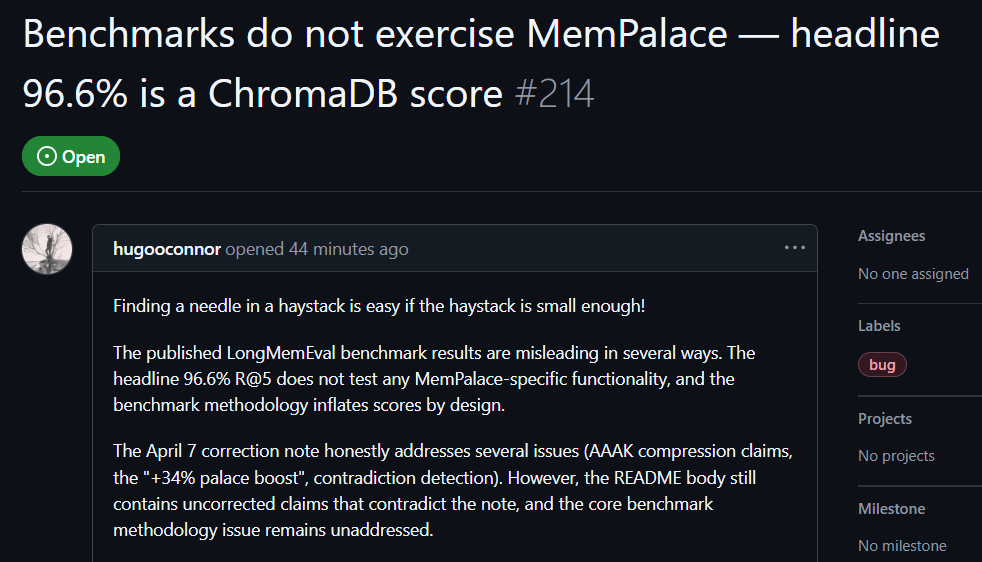
GitHubユーザーのhugooconnorは実測後にコメントし、MemPalaceが高い96.6%の検索精度をうたっているにもかかわらず、実際にはMemPalaceが売りにしているメモリー宮殿のアーキテクチャはまったく使われていないと述べました。hugooconnorによれば、彼らのテストは単に下層のデータベースChromaDBのデフォルト機能を呼び出しただけで、プロジェクトが強調する翼区画、部屋、引き出しなどの分類ロジックとは一切関係がないとのことです。
hugooconnorは、システムが実際にこれらのメモリー宮殿専用の分類ロジックを有効にすると、検索の成績がむしろ悪化することも確認しました。たとえば部屋モードでは精度が89.4%まで下がり、さらにAAAK圧縮技術を有効にすると精度は84.2%まで低下し、いずれもデフォルトのデータベースの性能より低くなっています。
hugooconnorはテスト方法も批判しており、MemPalaceのテスト環境は、各問題の検索範囲を意図的に約50の会話段階にまで縮小し、ごく小規模なサンプルのデータ庫の中から答えを探すのは簡単すぎると指摘しました。
検索範囲を実際の状況に近い19,000件以上の会話段階まで広げると、従来のキーワード検索の精度は30%まで暴落し、MemPalaceの現状のテスト方法が実際の検索の難しさを隠していることが示されています。
画像出典:GitHub GitHubユーザーの実測で、MemPalaceのベンチマークにミスリード要素がある
一方で、開発チームは訂正声明をすでに公開しており、AAAK技術が確かにロス圧縮で検証されていることを認め、コミュニティの厳しい批判に基づいて説明文書やシステム設計を修正すると約束しています。ただしプロジェクトのメインの説明文書は依然として、多数の未修正の誇張表現を残しています。たとえば「30倍のロスレス圧縮」や「34%の検索向上」といった主張、そして他の競合相手との比較図表にも出典がまったくありません。
MemPalaceの元コードは複数のBugに直面
より多くの開発者がテストをダウンロードするにつれ、現在GitHub上でMemPalaceの元コードに関する大量のBug報告が出ています。
ユーザーのcktang88は複数の重大な不備を列挙しており、圧縮コマンドが動作せずシステムがクラッシュする、要約の文字数計算ロジックに誤りがある、部屋を掘り起こす統計データが不正確である、そしてサーバーが呼び出しのたびにすべての解釈データをメモリに読み込むため、深刻なリソース消費問題が発生しているとしています。
その他指摘されている問題には、システムが開発者の家族の名前をデフォルト設定ファイルに強制的に書き込むことや、問い合わせステータス時に1万件のデータの強制表示上限が存在することなども含まれます。
これらの問題に対して、オープンソースコミュニティはすでに積極的な修復を開始しています。**ユーザーのadv3nt3が複数の修復リクエストを提出し、掘り起こしの統計データの修正、デフォルトの家族名の削除、知識グラフの初期化時間の遅延などを含みます。**開発チームも後にこれらの誤りを認めており、コミュニティの協力で段階的にコードの問題を解決しています。
ミラ・ジョヴォヴィッチのVibe Codingはかっこいいが、マーケティングはかっこよくない
MemPalaceというプロジェクトについて、Hacker Newsのユーザーdarkhanakhは次の結論を下しました。MemPalaceはOpenClawのような既視感があり、つまりベンチマーク結果を人為的に操作して完璧に見せ、その後それを何らかの重大なブレークスルーとして包んでマーケティングしている。
彼は、MemPalaceの基盤技術は確かに面白い可能性があるものの、テスト方法にこのような不備があるにもかかわらず、それでも「史上公開最高得点」を宣伝しているのはあまり適切ではないと考えています。「ただし、ミラ・ジョヴォヴィッチがVibe Codingをしている件は、俺としてはやっぱりかなりクールだと思う。」
関連記事:
AIがプログラミングでミスをやらかす!コンビニの期限切れ商品アプリ「惜食獵人」でサイバーセキュリティ問題、家のGPSが丸見え