As inference workloads scale from test clusters to real-world business applications, the default optimal solution is no longer always "everything centralized in ultra-large-scale data centers." This article examines the layered logic of edge nodes, regional data centers, and central clusters from the perspectives of latency, bandwidth, availability, and compliance. It explains key points in task partitioning, data boundaries, and operational governance within hybrid topologies, and provides a comparative overview against the broader AI infrastructure chain.
Public narratives often equate AI hash power with "ultra-large-scale data centers plus high-end GPUs." For training and certain centralized inference scenarios, this definition generally applies. AI Infrastructure features inference requests that are widely distributed, latency-sensitive, and require data to remain within domain, while network interruptions or peak congestion are unacceptable. In these cases, inference topology becomes an infrastructure issue: hash power must not only be available, but also located in "the right geographic position and the right network layer."
If AI infrastructure is viewed as a continuous chain, extending from the chip level up through services and governance, this article focuses on topology and deployment forms: how to allocate compute and data among edge, regional, and central layers to balance latency, cost, availability, and compliance. Upstream topics such as power, packaging, and HBM are better suited for supply-side discussions, while enterprise-level multi-model routing and agent governance details complement production operations.
Why Discuss "Distributed Inference Topology"
Centralized inference offers unified operations, flexible scaling, and high resource utilization. However, when business exhibits any of the following characteristics, topology decisions significantly impact experience and cost:
-
Strong latency constraints: Industrial control, real-time interaction, audio/video links, and offline retail locations are sensitive to tail latency; overly long return paths amplify jitter.
-
Data sovereignty and residency: Scenarios such as personal information, financial transactions, government services, and healthcare often require data to remain within domain, within borders, or within designated regions.
-
Return bandwidth and cost: Massive endpoints continuously upload raw data to central inference, making backbone network and egress fees potential primary cost drivers.
-
Availability and resilience: In the event of wide-area network failures, DNS fluctuations, or cross-region congestion, purely central architectures are more prone to cascading risks of "site-wide unavailability."
-
Offline or weak network: Environments like mines, ships, and certain manufacturing sites require local operational capability, rather than strong reliance on real-time online connectivity.
These challenges cannot be solved simply by "stronger central models," as their core issues lie in physical distance, network paths, and policy boundaries—not in the peak hash power of a single inference.
Layered Deployment: What Do Edge, Regional, and Central Layers Solve
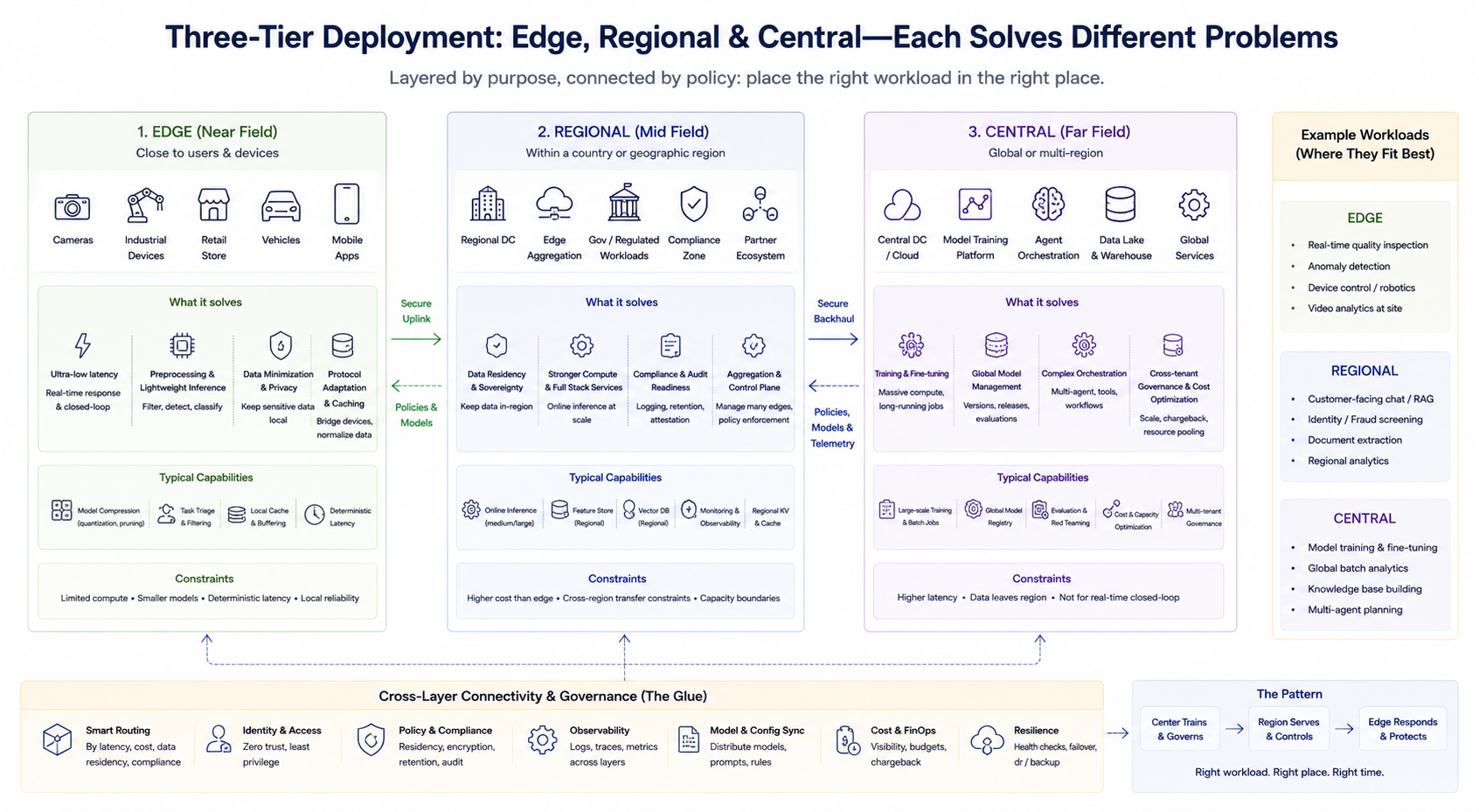
The typical engineering approach is not a binary choice, but a layered combination. A simplified framework helps clarify the responsibilities of each layer (specific naming may vary by provider):
Edge Layer (Near Field)
Positioned close to users or devices, this layer handles low-latency preprocessing, lightweight inference, caching, and protocol adaptation. It is ideal for real-time closed loops and minimizing sensitive data uploads. Edge hash power is usually limited, so model compression, task pruning, and deterministic latency are emphasized.
Regional Layer (Mid Field)
Provides stronger hash power and a more complete service stack within specific countries or geographic regions, meeting data residency, compliance auditing, and medium-scale aggregated inference needs. It also often serves as the aggregation and control plane for multiple edge nodes.
Central Layer (Far Field)
Handles training, large-scale batch processing, global model management, complex agent orchestration, unified cross-tenant governance, and cost optimization. It is suited for workloads that are less sensitive to latency but require high hash power and data aggregation.
These three layers are not fixed hierarchies, but are divided by business tasks. Enterprises may simultaneously operate central training, regional online inference, and edge real-time detection, routing requests to the appropriate layer according to routing strategies.
Task Partitioning: What Stays at the Edge, What Returns to the Center
Partitioning principles typically revolve around four axes: data minimization, latency budget, model complexity, and update frequency.
Tasks suited for the edge (assuming hash power requirements are met):
-
Real-time feature extraction, object detection, quality spot checks, and other low-latency closed loops
-
Lightweight inference after local desensitization (for example, uploading only feature vectors instead of raw media)
-
Fallback inference and cache hit strategies in weak network environments
Tasks suited for the center or region:
-
Agent workflows requiring large context, strong models, complex toolchains, or multi-system orchestration
-
Analytical inference requiring cross-department data aggregation
-
Sensitive calls requiring centralized auditing and unified key management
Common partitioning mistakes include forcing large models with long context onto the edge, resulting in OOM, or sending closed loops requiring low latency entirely back to the center, causing production line rhythm disruptions. The goal of topology design is not "the more edge, the better," but to place the right workload in the right location under constraints.
Data Sovereignty and Compliance: Topology Drives Architecture
Data sovereignty requirements directly alter inference deployment forms. Models can be downloaded locally, but logs, caches, vector indexes, and call traces may still pose compliance risks. In practice, key questions include:
-
Which data must be stored and computed at the edge or regional layer
-
Which metadata can leave the region or go to the cloud, and whether anonymization and retention periods are needed
-
Whether cross-region usage of different model versions and vendors is permitted (to avoid "compliance drift")
-
Whether, during audit and forensics, the output can be reconstructed as "generated at a certain location, time, and based on specific data fragments"
The answers to these questions often determine whether a system can go live, more so than "whether the model is open source." In other words, compliance is not an add-on for edge inference, but an input condition for topology design.
Network, Power, and Operations: The Real Costs of Distributed Deployment
Distributed inference brings systemic costs that must be evaluated explicitly during planning:
-
Network: As edge and regional nodes increase, certificate management, dedicated lines / SD‑WAN, DNS, and traffic scheduling complexity rises. Tail latency is harder to govern under multipath conditions.
-
Power and Data Centers: Edge sites are dispersed, and the energy efficiency and cooling conditions per unit hash power may be weaker than large data centers; regional data centers are intermediate. Upstream power and rack delivery pace still constrain expansion speed, but the constraint shifts from "single campus" to "multi-point parallel."
-
Operations and Version Consistency: When models, prompts, routing strategies, and indexes are released at multiple points, version drift can occur. Unified release pipelines, rollback strategies, and health checks are needed, or troubleshooting costs will quickly erode the latency gains brought by the edge.
-
Security Scope Expansion: More nodes mean more certificates, more entry points, and more local storage media. Physical security and patch cycles at the edge are often weaker than central data centers, requiring targeted minimum privilege and remote control strategies.
Therefore, distributed topology is not simply "pushing hash power farther out," but shifting some operational and governance complexity closer to the business site. If organizational capabilities and platform tools do not keep pace, topology advantages are difficult to realize.
Relationship with Centralized Inference: How Hybrid Architectures Are Implemented
Most mature solutions adopt hybrid architectures: the center handles training, global policies, and heavy workloads; the region handles online services within compliance zones; the edge handles low latency and local resilience. Common engineering patterns include:
-
Layered caching and result reuse: The edge serves high-frequency requests, and misses are sent back to the center. Cache keys, TTL, and sensitive data policies must be defined.
-
Model splitting and small model fronting: The edge runs detection or classification small models, the center runs large model fusion and interpretation generation (evaluated per scenario).
-
Asynchronous return and aggregation: The edge makes real-time decisions, then asynchronously returns desensitized samples or metrics for model iteration and monitoring.
-
Unified control plane: Routing, quotas, monitoring, and key management are centralized as much as possible, with execution decentralized, to reduce the risk of "each edge as an isolated island."
The key to successful hybrid architectures is unified control plane plus layered execution plane—not simply increasing node count.
Conclusion
The essence of discussions on edge and distributed inference is not a "decentralization slogan," but engineering trade-offs among latency, bandwidth, compliance, and operational cost. As business moves from demo to scale, topology choices shape model forms, network architectures, and organizational processes. Overlooking this layer can result in strong central hash power but persistent instability at the front line.








