С масштабированием блокчейн-приложений ончейн-данные стали ключевым ресурсом для DeFi, ончейн-аналитики, ИИ-агентов и мультичейн-приложений. Однако необработанные данные блокчейна представлены в виде блоков, транзакций и журналов событий, что вынуждает разработчиков проходить сложные этапы извлечения и обработки. Эффективный доступ к ончейн-данным стал одной из главных задач при построении инфраструктуры Web3.
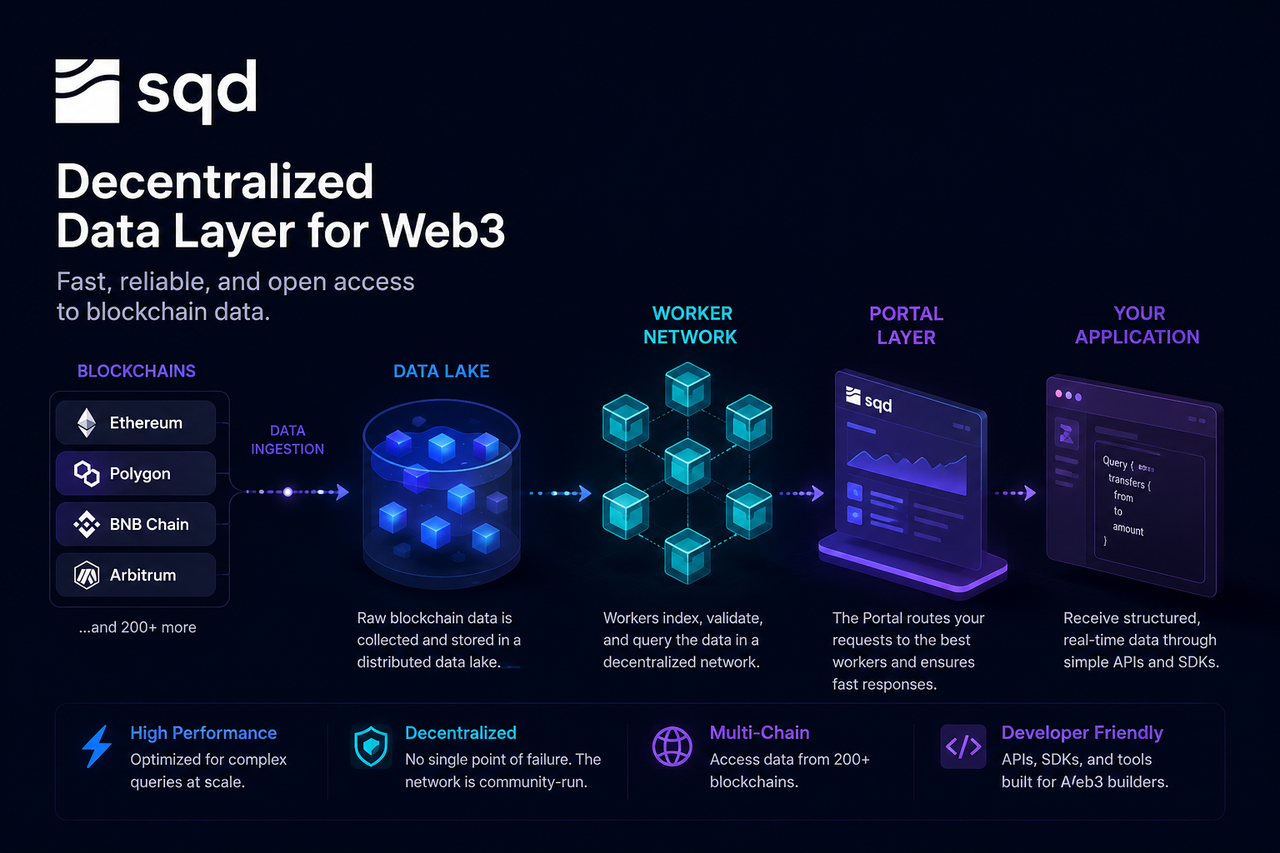
Subsquid (SQD) — это децентрализованная сеть данных, созданная для решения этой проблемы. В отличие от традиционных RPC-узлов, которые напрямую считывают состояние блокчейна, SQD предлагает архитектуру сервиса данных на основе озера данных, Узлов-обработчиков и уровня запросов Portal. Разработчики получают доступ к структурированным и проиндексированным ончейн-данным через единый интерфейс.
Что такое запрос данных SQD?
Запрос данных SQD — это способ получения разработчиками ончейн-данных через сеть SQD. Вместо прямого обращения к узлам блокчейна запросы SQD возвращают уже предварительно обработанные и проиндексированные данные, что позволяет быстро отвечать на сложные запросы.
Например, панель DeFi может агрегировать объемы торгов за последние несколько месяцев, ИИ-агенту может потребоваться считывать изменения активов по нескольким адресам, а аналитическая платформа — запрашивать полную историю событий конкретного смарт-контракта. Это типичные сценарии запросов.
Основная идея SQD — вынести обработку данных на этап подготовки, чтобы приложения получали структурированные данные напрямую, не обрабатывая огромные необработанные блоки.
Как ончейн-данные попадают в сеть SQD
Начальная точка запроса фактически находится до отправки запроса разработчиком.
По мере генерации новых блоков в сетях блокчейна сеть SQD в реальном времени захватывает необработанные данные — блоки, транзакции, события журналов и изменения состояния смарт-контрактов — через систему сбора данных. Затем данные стандартизируются для последующей обработки и хранения.
Поскольку SQD поддерживает несколько блокчейнов, уровень сбора данных должен непрерывно синхронизировать потоки данных из разных экосистем, обеспечивая целостность и согласованность. После стандартизации данные записываются в уровень хранения сети.
Как озеро данных хранит ончейн-информацию
Озеро данных — это основная инфраструктура хранения в сети SQD.
В отличие от традиционных баз данных, предназначенных для структурированных данных, озеро данных может обрабатывать большие объемы необработанных и полуструктурированных данных. История блокчейна, данные транзакций, журналы событий и снимки состояния — все это хранится в этом уровне.
Преимущество озера данных в том, что оно сохраняет полную историческую информацию, обеспечивая при этом гибкую последующую обработку и анализ. Для приложений, которым необходимо отследить миллионы транзакций, такой метод хранения гораздо эффективнее прямого запроса к узлам блокчейна.
Озеро данных действует как долговременная память сети SQD, предоставляя данные для последующей индексации и запросов.
Как узлы-обработчики обрабатывают запросы
Узлы-обработчики — это исполнительный уровень в сети SQD.
Когда данные поступают в сеть, узлы-обработчики индексируют, классифицируют и оптимизируют их для быстрого поиска. Процесс индексации напоминает создание оглавления для огромной энциклопедии — нет необходимости сканировать все с нуля для каждого запроса.
Помимо построения индексов, узлы-обработчики выполняют задачи запросов. Когда разработчик запрашивает определенные данные, узел-обработчик быстро находит соответствующие записи с помощью индекса, затем фильтрует, агрегирует и вычисляет результаты.
Поскольку несколько узлов-обработчиков могут работать параллельно, сеть может обрабатывать множество запросов одновременно, повышая общую производительность и масштабируемость.
Как Portal получает запросы разработчиков
Portal — это единая точка входа для разработчиков для доступа к сети SQD.
Разработчики обычно отправляют запросы через API или SDK, не подключаясь напрямую к базовым узлам. Когда запрос достигает Portal, система анализирует его и определяет, какие узлы-обработчики лучше всего подходят для его обработки.
Portal действует как балансировщик нагрузки в интернете. Разработчики взаимодействуют только с одним интерфейсом, в то время как сложное планирование ресурсов и выбор узлов происходят автоматически в фоновом режиме.
Такая конструкция упрощает разработку и повышает общую эффективность использования ресурсов сети.
Как результаты запроса возвращаются приложениям
После завершения обработки узлами-обработчиками результаты отправляются обратно на уровень Portal.
Portal форматирует результаты по мере необходимости и отправляет итоговые данные приложению. Разработчики получают уже структурированные данные — например, объекты JSON или результаты анализа — готовые для отображения во фронтенде, бизнес-логики или вывода ИИ.
Весь процесс обычно прозрачен для конечных пользователей. Они просто видят загрузку страницы или появление результатов анализа, в то время как за кулисами уже произошло множество шагов — от сбора данных до выполнения запроса.
Как Hotblocks поддерживает запросы данных в реальном времени
Помимо исторических запросов, многим приложениям требуется ончейн-информация в реальном времени.
Например, системы мониторинга ончейн должны обнаруживать аномальные транзакции, автоматизированные стратегии — прослушивать события смарт-контрактов, а ИИ-агенты — оставаться в курсе последних рыночных условий. Эти сценарии требуют, чтобы данные были доступны сразу после создания нового блока.
Hotblocks — это уровень данных в реальном времени, предоставляемый SQD, предназначенный специально для новых блоков и текущих событий. По сравнению с историческими данными в озере данных, Hotblocks ориентирован на низкую задержку и быстрый ответ, что позволяет разработчикам создавать приложения реального времени.
Чем запросы SQD отличаются от традиционных RPC-запросов
Оба метода позволяют получать доступ к ончейн-данным, но их внутренняя логика сильно различается.
Традиционные RPC-узлы подобны прямому запросу к базе данных блокчейна. Каждый запрос должен найти соответствующие данные из ончейн-состояния или исторических записей. С ростом объема запросов возрастает нагрузка на производительность и стоимость.
SQD, напротив, использует архитектуру с предварительной индексацией. Данные уже организованы и проиндексированы при поступлении в сеть, поэтому запросам не нужно повторно сканировать всю историю. Для сложного анализа, агрегации мультичейн-данных и долгосрочной исторической статистики SQD обычно предлагает гораздо более высокую эффективность.
| Измерение |
SQD |
Традиционный RPC |
| Источник данных |
Предварительно индексированные данные |
Ончейн-чтение в реальном времени |
| Эффективность запросов |
Высокая |
Средняя |
| Анализ исторических данных |
Значительное преимущество |
Более сложный |
| Поддержка нескольких цепочек |
Сильная |
Зависит от нескольких узлов |
| Стоимость инфраструктуры |
Ниже |
Выше |
| Чтение состояния в реальном времени |
Поддерживается |
Поддерживается |
Почему процесс запроса SQD важен для ИИ-агентов
ИИ-агенты становятся ключевым приложением в инфраструктуре Web3, и доступ к данным — основа их работы.
Если ИИ-агенту необходимо анализировать поведение кошельков, отслеживать состояния протоколов или выполнять ончейн-действия, он должен постоянно получать точные структурированные данные. Традиционные RPC-запросы могут предоставлять необработанные данные, но они обычно требуют дополнительной обработки и преобразования.
Единый интерфейс данных, предоставляемый SQD, снижает сложность получения ончейн-информации для ИИ-агентов. Благодаря стандартизированным результатам запросов системы ИИ могут направить больше вычислительной мощности на анализ и принятие решений, а не на обработку данных.
По мере продолжения конвергенции ИИ и Web3 важность децентрализованных уровней данных будет только возрастать.
Заключение
Запрос данных SQD — это не просто чтение данных; это полноценный рабочий процесс, в котором участвуют уровень сбора данных, озеро данных, узлы-обработчики и уровень Portal, работающие совместно. Необработанные данные блокчейна сначала собираются и сохраняются, затем индексируются и оптимизируются, и наконец доставляются разработчикам через единый интерфейс.
Эта модель предварительной индексации и распределенной обработки позволяет SQD обеспечивать высокую эффективность для сложных запросов, мультичейн-анализа и доступа к данным в реальном времени. По мере того как DeFi, платформы ончейн-аналитики и ИИ-агенты требуют все больше данных, архитектура уровня данных, представленная SQD, становится неотъемлемой частью инфраструктуры Web3.
Часто задаваемые вопросы
В чем разница между запросом данных SQD и обычным запросом API?
Обычный API обычно поддерживается централизованным провайдером, тогда как запрос SQD выполняется в децентрализованной сети данных. Данные SQD поступают из ончейн-систем сбора и индексации, что обеспечивает более открытый и проверяемый доступ к данным.
Почему скорость запросов SQD выше, чем у некоторых RPC-запросов?
SQD выполняет индексацию и организацию данных заранее, поэтому запросам не нужно повторно сканировать большие объемы истории блоков. Для сложного анализа и задач с историческими данными SQD обычно работает намного быстрее.
Какую роль играют узлы-обработчики в процессе запроса?
Узлы-обработчики отвечают за индексацию, фильтрацию, агрегацию и вычисления. Когда Portal получает запрос, соответствующие узлы-обработчики выполняют фактическую обработку данных.
В чем разница между озером данных и базой данных?
База данных обычно хранит структурированные данные, тогда как озеро данных может хранить огромные объемы необработанных и полуструктурированных данных. SQD использует озеро данных для хранения полной ончейн-истории, поддерживая гибкие запросы и анализ.
Может ли Hotblocks заменить исторические запросы данных?
Нет. Hotblocks предназначен для доступа к данным в реальном времени; исторические запросы по-прежнему опираются на озеро данных и систему индексации. Вместе они образуют полный набор сервисов данных SQD.
Какие приложения лучше всего подходят для сервисов запросов SQD?
Панели DeFi, блокчейн-обозреватели, платформы ончейн-аналитики, системы мониторинга в реальном времени, мультичейн-приложения и ИИ-агенты — любой сценарий, требующий частого доступа к ончейн-данным, идеально подходит для сервисов запросов SQD.







