У міру масштабування інференс-навантажень від тестових кластерів до реальних бізнес-застосунків оптимальним рішенням вже не завжди є «централізація всього в ультравеликих дата-центрах». У цій статті розглядається багаторівнева логіка крайових нод, регіональних дата-центрів і центральних кластерів із точки зору затримки, пропускної здатності, доступності та відповідності. Описано ключові моменти поділу завдань, меж даних і операційного управління в гібридних топологіях, а також подано порівняльний огляд щодо ширшого ланцюга інфраструктури ШІ.
У професійних обговореннях хеш-потужність ШІ часто прирівнюють до «ультравеликих дата-центрів і високопродуктивних GPU». Для тренування і певних централізованих сценаріїв інференсу це визначення застосовується. Інфраструктура ШІ охоплює інференс-запити, які широко розподілені, чутливі до затримки й вимагають збереження даних у межах домену, тоді як мережеві збої чи пікові перевантаження є неприпустимими. У таких випадках топологія інференсу стає питанням інфраструктури: хеш-потужність має бути не лише доступною, а й розташованою «у потрібному географічному місці й на потрібному мережевому рівні».
Якщо розглядати інфраструктуру ШІ як безперервний ланцюг — від рівня чипів до сервісів і управління, — ця стаття фокусується на топології й формах розгортання: як розподілити обчислення та дані між крайовим, регіональним і центральним рівнями для балансу затримки, вартості, доступності й відповідності. Теми енергоживлення, пакування та HBM більше стосуються постачальників, а корпоративна маршрутизація мультимоделей і деталі агентного управління — виробничих операцій.
Чому варто обговорювати «розподілену топологію інференсу»
Централізований інференс забезпечує уніфіковані операції, гнучке масштабування та високе використання ресурсів. Проте, коли бізнес має одну з таких характеристик, рішення щодо топології суттєво впливають на досвід і вартість:
-
Жорсткі обмеження по затримці: промислове керування, взаємодія в реальному часі, аудіо/відео-з'єднання та офлайн-торгівля чутливі до пікової затримки; надто довгі зворотні маршрути підсилюють джиттер.
-
Суверенітет і локалізація даних: у випадках персональних даних, фінансових операцій, державних сервісів і охорони здоров’я часто потрібно, щоб дані залишалися в домені, у межах кордонів або визначених регіонів.
-
Зворотна пропускна здатність і вартість: масові кінцеві точки постійно завантажують сирі дані до центрального інференсу, що робить витрати на магістральні мережі та вихідні канали ключовими драйверами вартості.
-
Доступність і стійкість: у разі збоїв у мережі, коливань DNS чи міжрегіональних перевантажень суто центральна архітектура більш схильна до каскадних ризиків «недоступності всієї локації».
-
Офлайн або слабка мережа: у середовищах, як-от шахти, судна чи окремі виробничі майданчики, потрібна локальна працездатність, а не залежність від постійного онлайн-з'єднання.
Ці виклики не вирішуються просто «потужнішою центральною моделлю», оскільки їхня суть — у фізичній відстані, мережевих маршрутах і політичних межах, а не у піковій хеш-потужності одного інференсу.
Багаторівневе розгортання: які завдання вирішують крайовий, регіональний і центральний рівні
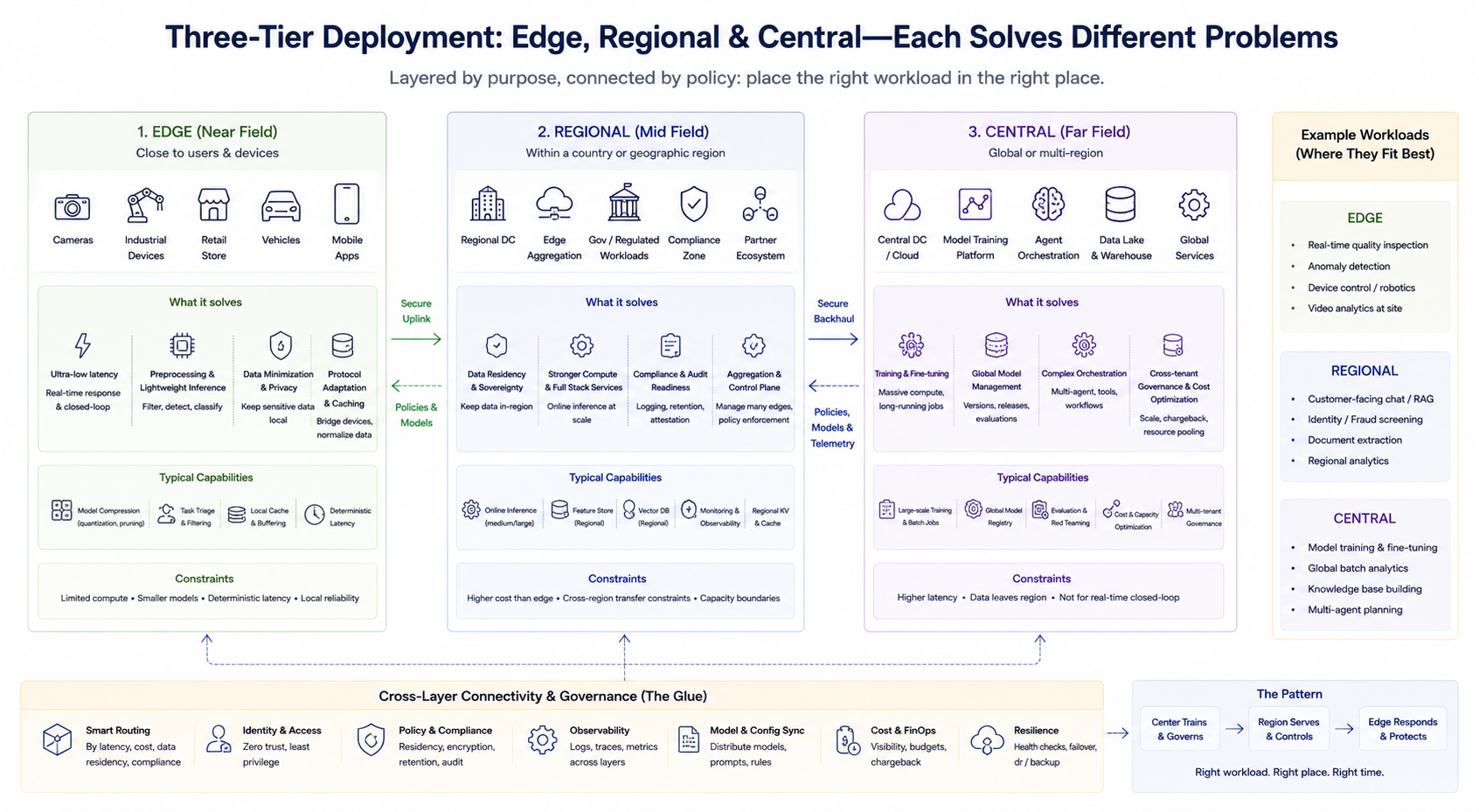
Типовий інженерний підхід — це багаторівневе поєднання, а не бінарний вибір. Спрощена схема допомагає зрозуміти відповідальність кожного рівня (назви можуть відрізнятися залежно від провайдера):
Крайовий рівень (ближнє поле)
Розташований поруч із користувачами або пристроями, цей рівень забезпечує обробку з малою затримкою, легкий інференс, кешування та адаптацію протоколів. Він ідеально підходить для замкнених контурів у реальному часі й мінімізації завантажень чутливих даних. Хеш-потужність на краю зазвичай обмежена, тому акцент робиться на стисненні моделей, обрізанні завдань і детермінованій затримці.
Регіональний рівень (середнє поле)
Забезпечує більшу хеш-потужність і повніший сервісний стек у межах країни чи географічного регіону, відповідає вимогам локалізації даних, аудиту відповідності та середньомасштабного агрегованого інференсу. Також часто виконує роль площини агрегації й управління для кількох крайових нод.
Центральний рівень (далеке поле)
Відповідає за тренування, великомасштабну пакетну обробку, глобальне управління моделями, складну оркестрацію агентів, уніфіковане крос-орендарське управління та оптимізацію витрат. Призначений для навантажень, менш чутливих до затримки, але таких, що потребують високої хеш-потужності й агрегації даних.
Ці три рівні не є жорсткою ієрархією, а поділяються за бізнес-завданнями. Підприємства можуть одночасно виконувати центральне тренування, регіональний онлайн-інференс і крайове виявлення в реальному часі, спрямовуючи запити на відповідний рівень згідно з маршрутними стратегіями.
Поділ завдань: що залишати на краю, а що повертати в центр
Принципи поділу зазвичай базуються на чотирьох осях: мінімізація даних, бюджет затримки, складність моделі та частота оновлень.
Завдання, що підходять для краю (за умови достатньої хеш-потужності):
-
Виділення ознак у реальному часі, виявлення об’єктів, контроль якості та інші замкнені контури з низькою затримкою
-
Легкий інференс після локальної десенсибілізації (наприклад, завантаження лише векторів ознак замість сирих медіаданих)
-
Резервний інференс і стратегії кешування у слабких мережах
Завдання для центру або регіону:
-
Агентні робочі процеси, що потребують великого контексту, потужних моделей, складних інструментів чи мультисистемної оркестрації
-
Аналітичний інференс із необхідністю агрегування даних між підрозділами
-
Чутливі виклики, які вимагають централізованого аудиту та уніфікованого управління ключами
Типові помилки поділу — це спроба розмістити великі моделі з довгим контекстом на краю, що призводить до OOM, або відправлення замкнених контурів із низькою затримкою повністю в центр, що порушує ритм виробничої лінії. Мета топологічного дизайну — розміщення потрібного навантаження у відповідному місці з урахуванням обмежень, а не «чим більше краю, тим краще».
Суверенітет даних і відповідність: топологія визначає архітектуру
Вимоги до суверенітету даних безпосередньо змінюють форми розгортання інференсу. Моделі можна завантажити локально, але логи, кеші, векторні індекси й трасування викликів усе ще можуть нести ризики невідповідності. На практиці ключові питання такі:
-
Які дані потрібно зберігати й обробляти на крайовому або регіональному рівні
-
Які метадані можна вивозити за межі регіону чи в хмару, і чи потрібна анонімізація та обмеження строків зберігання
-
Чи дозволено кросрегіональне використання різних версій моделей і провайдерів (щоб уникнути «дрейфу відповідності»)
-
Чи можна під час аудиту й розслідування відтворити результат як «згенерований у певному місці, у певний час і на основі конкретних фрагментів даних»
Відповіді на ці питання часто визначають можливість запуску системи більше, ніж «чи є модель відкритою». Відповідність — це не доповнення для крайового інференсу, а вихідна умова для проектування топології.
Мережа, енергоживлення й операції: справжня вартість розподіленого розгортання
Розподілений інференс несе системні витрати, які потрібно чітко враховувати на етапі планування:
-
Мережа: зі збільшенням крайових і регіональних нод зростає складність керування сертифікатами, виділеними лініями / SD‑WAN, DNS і маршрутизацією трафіку. Пікову затримку важче контролювати в умовах багатьох маршрутів.
-
Енергоживлення і дата-центри: крайові майданчики розосереджені, а енергоефективність і охолодження на одиницю хеш-потужності можуть бути слабшими, ніж у великих дата-центрах; регіональні — проміжні. Темпи підключення живлення й стійок усе ще обмежують швидкість розширення, але обмеження зміщується з «одного кампусу» на «багатоточковий паралелізм».
-
Операції й узгодженість версій: якщо моделі, підказки, маршрутизація й індекси випускаються у багатьох точках, виникає дрейф версій. Потрібні уніфіковані пайплайни випуску, стратегії відкоту й health-check, інакше витрати на усунення проблем швидко перекреслять виграш у затримці від краю.
-
Розширення периметру безпеки: більше нод — більше сертифікатів, точок входу й локальних носіїв. Фізична безпека й цикли патчів на краю часто слабші, ніж у центральних дата-центрах, тому потрібні цільові стратегії мінімальних привілеїв і віддаленого контролю.
Тому розподілена топологія — це не просто «винесення хеш-потужності далі», а перенесення частини операційної й управлінської складності ближче до місця бізнесу. Якщо організаційні можливості й платформені інструменти не розвиваються відповідно, переваги топології реалізувати складно.
Взаємозв’язок із централізованим інференсом: як реалізуються гібридні архітектури
Більшість зрілих рішень використовують гібридні архітектури: центр займається тренуванням, глобальними політиками й важкими навантаженнями; регіон — онлайн-сервісами у зонах відповідності; край — низькою затримкою й локальною стійкістю. Типові інженерні патерни:
-
Багаторівневе кешування й повторне використання результатів: край обслуговує часті запити, а пропуски йдуть у центр. Необхідно визначити ключі кешу, TTL і політики щодо чутливих даних.
-
Розділення моделей і запуск малих моделей на краю: край виконує виявлення чи класифікацію малими моделями, центр — злиття великих моделей і генерацію інтерпретацій (оцінюється за сценарієм).
-
Асинхронне повернення й агрегування: край приймає рішення в реальному часі, потім асинхронно надсилає десенсибілізовані вибірки чи метрики для ітерації моделі й моніторингу.
-
Уніфікована площина управління: маршрутизація, квоти, моніторинг і керування ключами централізуються максимально, а виконання децентралізується, щоб зменшити ризик «ізольованих островів».
Ключ до успішних гібридних архітектур — уніфікована площина управління плюс багаторівнева площина виконання, а не просто збільшення кількості нод.
Висновок
Суть дискусії про крайовий і розподілений інференс — не «гасло про децентралізацію», а інженерний компроміс між затримкою, пропускною здатністю, відповідністю й операційною вартістю. У міру переходу бізнесу від демо до масштабування вибір топології визначає форми моделей, мережеву архітектуру й організаційні процеси. Ігнорування цього рівня може призвести до потужної центральної хеш-потужності, але постійної нестабільності на передовій.









