Коротко
- ARC-AGI-3 виявляє величезний розрив між заявами про AGI та реальністю: провідні моделі ШІ показують менше 1%, тоді як люди досягають ідеальної роботи.
- Бенчмарк тестує справжню здатність до узагальнення — необхідно досліджувати, планувати та навчатися з нуля в невідомих середовищах, а не просто відтворювати натреновані шаблони.
- Попри галас у галузі, сучасні системи ШІ залишаються далекі від AGI, їм бракує логіки та адаптивності, які навіть молоді люди демонструють природно.
Генеральний директор Nvidia Дженсен Хуанг минулого тижня з’явився у подкасті Лекса Фрідмана і прямо сказав: «Я вважаю, що ми досягли AGI». Через два дні з’явився найжорсткіший тест у дослідженнях ШІ з новим бенчмарком штучного загального інтелекту — і всі передові моделі показали менше 1%.
Фонд ARC Prize цього тижня випустив ARC-AGI-3, і результати вражають. Gemini 3.1 Pro від Google показав 0,37%. GPT-5.4 від OpenAI — 0,26%. Claude Opus 4.6 від Anthropic — 0,25%, а Grok-4.20 від xAI — зовсім 0%. Люди ж розв’язали 100% середовищ.
Це не тест на знання або програмування, і навіть не складні питання рівня PhD. ARC-AGI-3 — це зовсім інше, ніж будь-який попередній виклик у галузі ШІ.
Бенчмарк створено Філіпом Шолле та Майком Кнопом, які заснували внутрішню ігрову студію і створили 135 оригінальних інтерактивних середовищ з нуля. Ідея — вставити агент ШІ у незнайомий ігровий світ без інструкцій, цілей або правил. Агент має досліджувати, з’ясувати, що потрібно робити, сформувати план і виконати його.
Якщо це звучить так, ніби будь-яка п’ятирічна дитина може це зробити, ви починаєте розуміти проблему. Якщо хочете перевірити, чи краще ви за ШІ, можете пограти у ті самі ігри, що й у тесті, за цим посиланням. Ми спробували одну — спочатку було дивно, але через кілька секунд все стало зрозуміло.
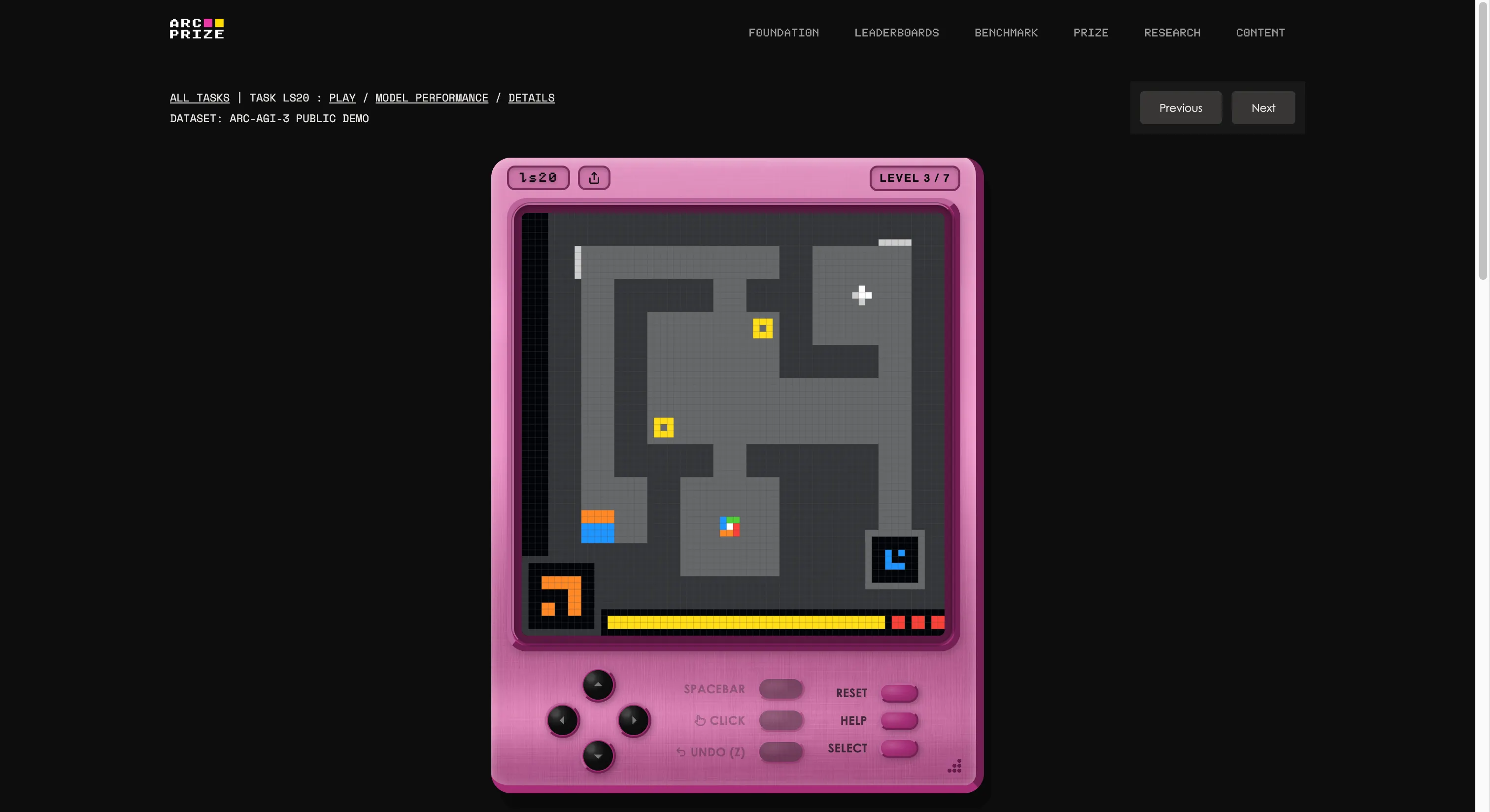
Це також найчіткіший приклад того, що означає буква “G” у AGI. Коли ви узагальнюєте, ви можете створювати нові знання (як працює дивна гра) без попереднього навчання.
Попередні версії ARC тестували статичні візуальні головоломки — показати шаблон, передбачити наступний. Спочатку вони були складними. Потім лабораторії додавали обчислювальну потужність і тренування, і бенчмарки фактично зникли. ARC-AGI-1, запущений у 2019 році, тестував моделі на основі тренувань під час тесту та логіки. ARC-AGI-2 тривав близько року, поки Gemini 3.1 Pro не досяг 77,1%. Лабораторії дуже добре насичують бенчмарки, на які можна тренуватися.
Версія 3 була створена спеціально, щоб цього уникнути. З 110 з 135 середовищ зроблено приватними — 55 напівприватних для API-тестування і 55 повністю закритих для змагань — datasets для запам’ятовування немає. Ви не можете грубо пройти через нову логіку гри, яку ніколи не бачили.
Оцінка також не є проходженням/непроходженням. ARC-AGI-3 використовує те, що називає фонд RHAE — Відносна Ефективність Людських Дій. Базовий рівень — це друга за ефективністю людська робота з першого запуску. ШІ, що робить у десять разів більше дій, отримує 1% за цей рівень, а не 10%. Формула підносить штраф за неефективність у квадраті. Блукання, повернення назад і здогадки караються суворо.
Найкращий агент ШІ у місячному тестовому режимі набрав 12,58%. Передові моделі LLM через офіційний API без додаткових інструментів не змогли подолати 1%. Звичайні люди розв’язали всі 135 середовищ без попереднього навчання і без інструкцій. Якщо це планка, то сучасні моделі ще не досягають її.
Є один справжній методологічний спір. Звіт ARC стверджує, що кастомний інструментарій, створений у Duke, підняв Claude Opus 4.6 з 0,25% до 97,1% на одному варіанті середовища TR87. Це не означає, що Claude набрав 97,1% у цілому за ARC-AGI-3; його офіційний бал залишився 0,25%, але цей зсув все ж вартий уваги.
Офіційний бенчмарк подає агентам JSON-код, а не візуальні зображення. Це або методологічна помилка, або демонстрація того, що сучасні моделі краще обробляють людську зрозумілу інформацію, ніж сирі структуровані дані. Фонд Шолле визнав цей спір, але формат не змінює.
“Сприйняття змісту кадру та формат API не є обмежуючими факторами для продуктивності передових моделей на ARC-AGI-3,” — йдеться у документі. Іншими словами, вони заперечують ідею, що моделі не справляються через неспроможність “бачити” завдання належним чином, стверджуючи, що сприйняття вже достатнє — і справжня різниця полягає у логіці та здатності до узагальнення.
Реальність AGI підтверджується у тиждень, коли галас навколо нього був на піку. Крім коментаря Хуанга, Arm назвала свій новий дата-центрний чип “AGI CPU”. Сам Альтман з OpenAI заявив, що вони “фактично створили AGI”, а Microsoft вже просуває лабораторію, яка працює над створенням ASI — еволюції того, що станеться після досягнення AGI. Терміни розтягнули так, що вони тепер означають усе, що зручно з комерційної точки зору.
Позиція Шолле проста. Якщо звичайна людина без інструкцій може це зробити, а ваша система — ні, то у вас немає AGI — є дуже дорогий автозаповнювач, який потребує багато допомоги.
ARC Prize 2026 пропонує 2 мільйони доларів у трьох конкурсних напрямках, усі на Kaggle. Кожне рішення має бути відкритим. Час іде, і наразі машини навіть близько не підходять до цієї мети.
Застереження: Інформація на цій сторінці може походити від третіх осіб і не відображає погляди або думки Gate. Вміст, що відображається на цій сторінці, є лише довідковим і не є фінансовою, інвестиційною або юридичною порадою. Gate не гарантує точність або повноту інформації і не несе відповідальності за будь-які збитки, що виникли в результаті використання цієї інформації. Інвестиції у віртуальні активи пов'язані з високим ризиком і піддаються значній ціновій волатильності. Ви можете втратити весь вкладений капітал. Будь ласка, повністю усвідомлюйте відповідні ризики та приймайте обережні рішення, виходячи з вашого фінансового становища та толерантності до ризику. Для отримання детальної інформації, будь ласка, зверніться до
Застереження.

