EncryptedKFA
現在、コンテンツはありません
EncryptedKFA
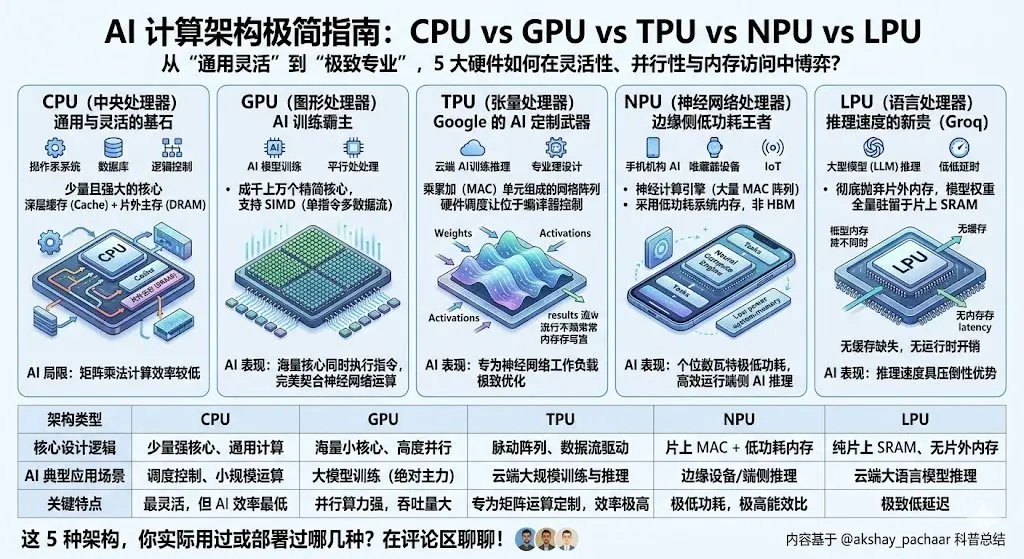
現在のAIは5つのハードウェアアーキテクチャによって支配されており、それぞれが柔軟性、並列性、メモリアクセスの間で異なるトレードオフを行っている。
CPU:汎用計算設計で、少数の強力なコアのみを持ち、複雑な論理、分岐判断、システムレベルのタスクに優れる。深いキャッシュと外部DRAM(メインメモリ)を備え、OSやデータベースなどに適しているが、神経ネットワークに必要な繰り返し行われる行列乗算にはあまり効率的でない。
GPU:少数の強力なコアではなく、何千もの小さなコアが同時に同じ命令を実行(SIMD)する。高い並列性が神経ネットワークの数学演算に完璧に適合し、AIのトレーニングを主導している。
TPU(Google設計):さらに専門化。コアは乗算累加(MAC)ユニットのグリッドで構成され、データは「波」の形で流れる——重みは一方から入り、活性化値はもう一方から入り、結果は直接伝播し、メモリへの書き戻しは不要。全体の実行はコンパイラによって制御され(ハードウェアのスケジューリングではない)、神経ネットワークの負荷に最適化されている。
NPU(Neural Processing Unit):エッジデバイス向けの最適化版。Neural Compute Engine(大量のMACアレイ+オンチップSRAM)を内蔵しているが、高帯域幅のHBMではなく低消費電力のシステムメモリを使用。スマートフ
原文表示CPU:汎用計算設計で、少数の強力なコアのみを持ち、複雑な論理、分岐判断、システムレベルのタスクに優れる。深いキャッシュと外部DRAM(メインメモリ)を備え、OSやデータベースなどに適しているが、神経ネットワークに必要な繰り返し行われる行列乗算にはあまり効率的でない。
GPU:少数の強力なコアではなく、何千もの小さなコアが同時に同じ命令を実行(SIMD)する。高い並列性が神経ネットワークの数学演算に完璧に適合し、AIのトレーニングを主導している。
TPU(Google設計):さらに専門化。コアは乗算累加(MAC)ユニットのグリッドで構成され、データは「波」の形で流れる——重みは一方から入り、活性化値はもう一方から入り、結果は直接伝播し、メモリへの書き戻しは不要。全体の実行はコンパイラによって制御され(ハードウェアのスケジューリングではない)、神経ネットワークの負荷に最適化されている。
NPU(Neural Processing Unit):エッジデバイス向けの最適化版。Neural Compute Engine(大量のMACアレイ+オンチップSRAM)を内蔵しているが、高帯域幅のHBMではなく低消費電力のシステムメモリを使用。スマートフ
- 報酬
- いいね
- コメント
- リポスト
- 共有
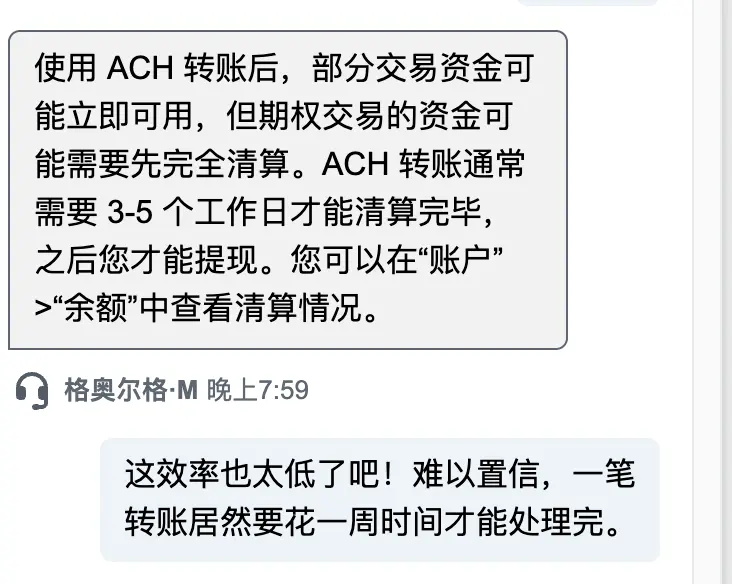
先週日、WISEからジェイコブ・キャピタルにお金を送金した
今もまだ入金されていない
これは暗号通貨界のネイティブにとって信じられないほど非効率だ
原文表示今もまだ入金されていない
これは暗号通貨界のネイティブにとって信じられないほど非効率だ
- 報酬
- いいね
- コメント
- リポスト
- 共有
一通り見てみると、多くの人が引退している。暗号通貨界を離れた彼らは一体どこへ行ったのだろうか?
原文表示- 報酬
- いいね
- コメント
- リポスト
- 共有
大A一出手就跌停??
- 報酬
- いいね
- コメント
- リポスト
- 共有
あなたは受け取る資格があるかどうか確認してください。 $Whalecoin
原文表示
- 報酬
- いいね
- コメント
- リポスト
- 共有
ほとんど手数料が貼り付けられそうになった $prespax
原文表示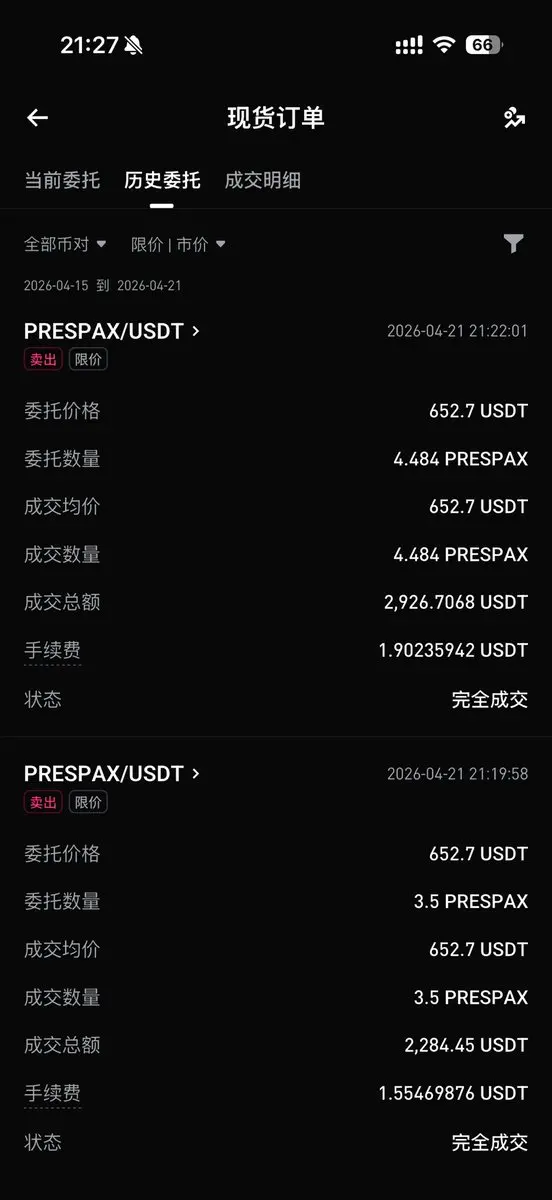
- 報酬
- いいね
- コメント
- リポスト
- 共有
ホットスポットはどこにある➡️流動性はどこにある➡️流動性はどこにある➡️雷はどこにある
原文表示- 報酬
- いいね
- コメント
- リポスト
- 共有
ほとんどの場合:
高値を追う方が底値を拾うよりも稼ぎやすい
買いポジションを取る方が空売りよりも稼ぎやすい
原文表示高値を追う方が底値を拾うよりも稼ぎやすい
買いポジションを取る方が空売りよりも稼ぎやすい
- 報酬
- いいね
- コメント
- リポスト
- 共有
Circle(USDC発行者)のCEOジェレミー・アレアは、香港でロイターのインタビューに応じて、「人民元のステーブルコインには巨大な可能性がある」と述べました。(人民币稳定币存在巨大机会)。彼はまた、中国が今後3〜5年以内に人民元をサポートするステーブルコインを導入する可能性があると考えています。
USDC0.01%

- 報酬
- いいね
- コメント
- リポスト
- 共有
みんなツイッターで絶賛しているけど、数ヶ月前に購入したテルポペチドを今日やっと勇気を出して打った。もしかして私だけ本気にしてるのかな?
原文表示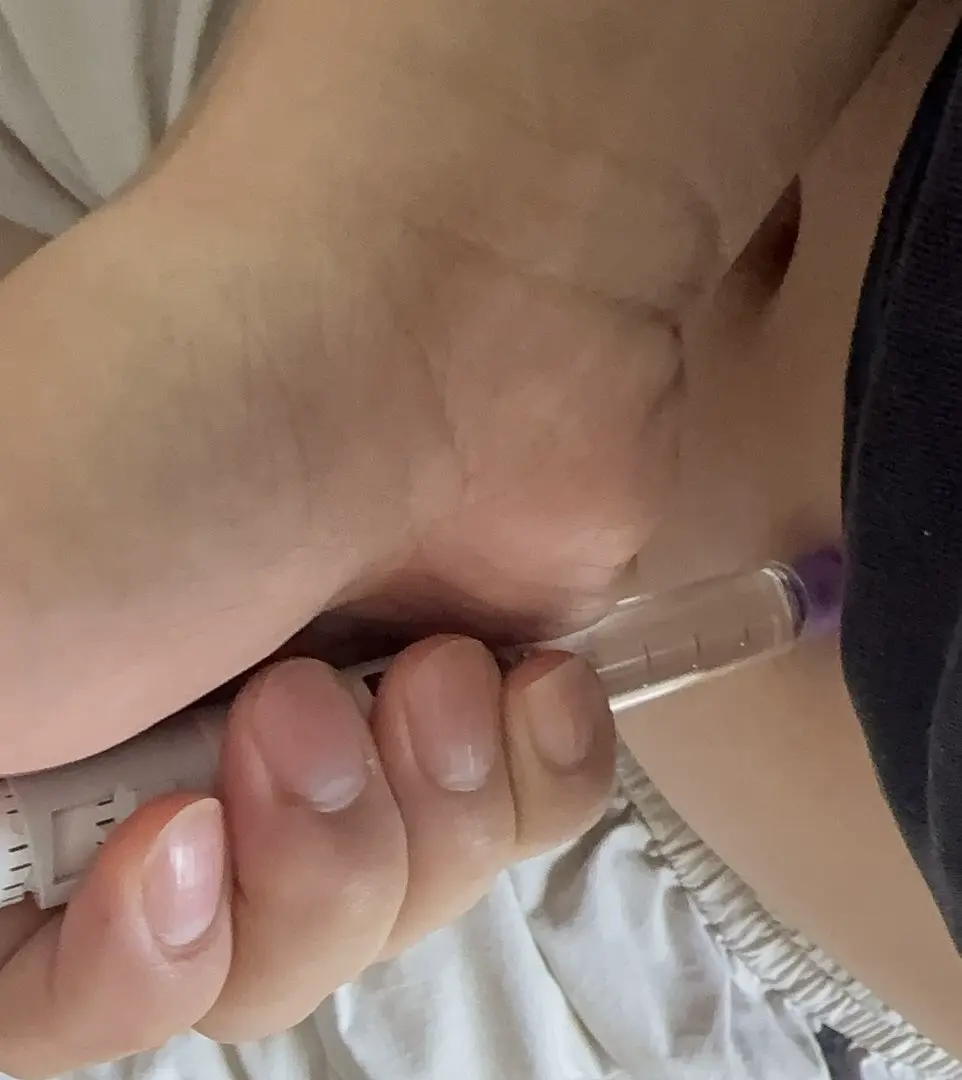
- 報酬
- 2
- コメント
- リポスト
- 共有
友達に尋ねたことです
合規=操縱できない=拉盤できないのか
原文表示合規=操縱できない=拉盤できないのか
- 報酬
- いいね
- コメント
- リポスト
- 共有
資産運用の年利回りがどんどん低くなっている
もっと年利回りを向上させる方法を学ぶ必要がある
いくつかの出入金ルートをテストした
いくつかの証券会社をテストした
➡️ワイズ➡️ジェイソン・リバティ
➡️ジョン・アン➡️ワイズ➡️ジェイソン・リバティ
➡️ジョン・アン➡️電信送金ジェイソン・リバティ
今日最初に開いたPUT売りのテスト注文
ジェイソン・リバティを使った
一通りの流れを行う
正直、初心者にはあまり理解できない
すべてAIに任せて進めている
原文表示もっと年利回りを向上させる方法を学ぶ必要がある
いくつかの出入金ルートをテストした
いくつかの証券会社をテストした
➡️ワイズ➡️ジェイソン・リバティ
➡️ジョン・アン➡️ワイズ➡️ジェイソン・リバティ
➡️ジョン・アン➡️電信送金ジェイソン・リバティ
今日最初に開いたPUT売りのテスト注文
ジェイソン・リバティを使った
一通りの流れを行う
正直、初心者にはあまり理解できない
すべてAIに任せて進めている
- 報酬
- いいね
- コメント
- リポスト
- 共有
質の高い資産運用は、暗号通貨界における資金保持の最後の願いです。
原文表示- 報酬
- いいね
- コメント
- リポスト
- 共有
の統一アカウントは @Backpack と比べるとかなり劣る。もしかすると使い慣れているから使い勝手が良く感じるだけかもしれないし、収益面でもバックパックの方が快適だ。
原文表示
- 報酬
- 1
- コメント
- リポスト
- 共有
の統一アカウントは @Backpack と比べるとかなり劣る。
多く使うと使い勝手が良いと感じるかもしれないが、収益面では背包の方が快適だ。
原文表示多く使うと使い勝手が良いと感じるかもしれないが、収益面では背包の方が快適だ。
- 報酬
- 1
- コメント
- リポスト
- 共有