Após o avanço acelerado das capacidades dos grandes modelos, as empresas passaram a se preocupar menos com “a disponibilidade de um modelo” e mais com “a capacidade de operar de forma confiável e sustentável em ambientes reais de negócios”. Enquanto clusters de treinamento agregam poder de hash, sistemas de produção precisam lidar com solicitações contínuas, latência de cauda, iteração de versões, permissões de dados e responsabilização por incidentes. Em resumo, o foco central da IA corporativa está migrando para frameworks de inferência e operação. Os agentes ampliam os desafios de “Q&A de turno único” para “tarefas de múltiplas etapas, uso de ferramentas e gestão de estado”, elevando significativamente os requisitos de infraestrutura e governança.
Ao considerar a infraestrutura de IA como uma cadeia contínua — dos chips aos data centers, serviços e governança — este artigo aborda o ponto final: serviços de inferência, acesso a dados e governança organizacional. Temas como HBM, energia e data centers são melhor discutidos sob a ótica da oferta; este texto parte do pressuposto de que o leitor já compreende arquiteturas em camadas.
Por que “Inferência em Produção” e “Poder de Hash de Treinamento” são Desafios Distintos
Embora treinamento e inferência compartilhem recursos como GPUs, redes e armazenamento, seus objetivos de otimização são diferentes. O treinamento prioriza throughput e paralelismo de longa duração; a inferência foca em concorrência, latência de cauda, custo por requisição, além de cadência de versões e rollbacks. Para empresas, essas diferenças impactam diretamente as escolhas de arquitetura e limites de aquisição:
-
Estrutura de custos: O treinamento é normalmente um investimento de capital em etapas, enquanto os custos de inferência crescem linearmente com o volume de negócios e são mais sensíveis a cache, batching, roteamento e seleção de modelo.
-
Definição de disponibilidade: Treinamentos podem ser enfileirados e reexecutados; a inferência online costuma exigir SLAs, com limitação de taxa, degradação e estratégias de múltiplas réplicas.
-
Frequência de mudanças: Atualizações de modelo, prompt, política de ferramentas e base de conhecimento são mais frequentes, exigindo processos de liberação auditáveis em vez de implantações únicas.
-
Limites de dados: Dados de treinamento costumam estar em ambientes controlados, enquanto a inferência acessa dados de clientes, documentos internos e sistemas de negócios, exigindo permissões mais rigorosas e mascaramento de dados.
Por isso, ao avaliar a infraestrutura de IA corporativa, é mais eficiente focar nas capacidades da camada de serviço — gateways, roteamento, observabilidade, liberação, permissões e auditoria — do que apenas comparar o tamanho dos clusters de treinamento.
Stack de Inferência em Produção: Do Entry à Observabilidade
Uma stack robusta de inferência inclui pelo menos os seguintes módulos. Embora os fornecedores possam usar nomes diferentes, as funções principais são as mesmas.
API Gateway e Governança de Tráfego
Ponto de entrada unificado para autenticação, cotas, limitação de taxa e terminação TLS; ao expor capacidades do modelo externamente, o gateway é a primeira linha de defesa para segurança e estratégia de negócios.
Roteamento de Modelos e Gestão de Versões
Empresas frequentemente executam múltiplos modelos ao mesmo tempo (para tarefas, custos e compliance distintos). O roteamento deve permitir desvio por locatário, cenário e nível de risco, além de releases em cinza e rollbacks, evitando falhas por substituições “todas de uma vez”.
Serialização, Batching e Caching
Sob alta concorrência, serialização/desserialização, estratégias de batching e design de cache KV ou semântico impactam fortemente a latência de cauda e o custo. O uso de cache também traz riscos de consistência, exigindo políticas claras de invalidação e tratamento de dados sensíveis.
Recuperação Vetorial e Integração RAG (se aplicável)
A geração aumentada por recuperação conecta a inferência aos sistemas de dados: atualização de índices, filtragem por permissão, exibição de fragmentos de referência e controle de risco de alucinação são parte essencial do framework operacional, e não “adicionais” externos ao modelo.
Observabilidade, Log e Apuração de Custos
No mínimo, o uso de tokens, percentis de latência e tipos de erro devem ser detalhados por locatário, versão do modelo e política de roteamento. Sem isso, o planejamento de capacidade é comprometido e revisões pós-incidente não conseguem identificar se o problema veio do modelo, dos dados ou do gateway.
Esses módulos determinam a estabilidade da experiência online, o controle de custos e a rastreabilidade dos problemas. A ausência de qualquer componente resulta em sistemas que funcionam em demonstrações de baixa carga, mas falham em picos de uso ou mudanças.
Multi-Modelo e Deploy Híbrido: Roteamento, Custo e Soberania de Dados
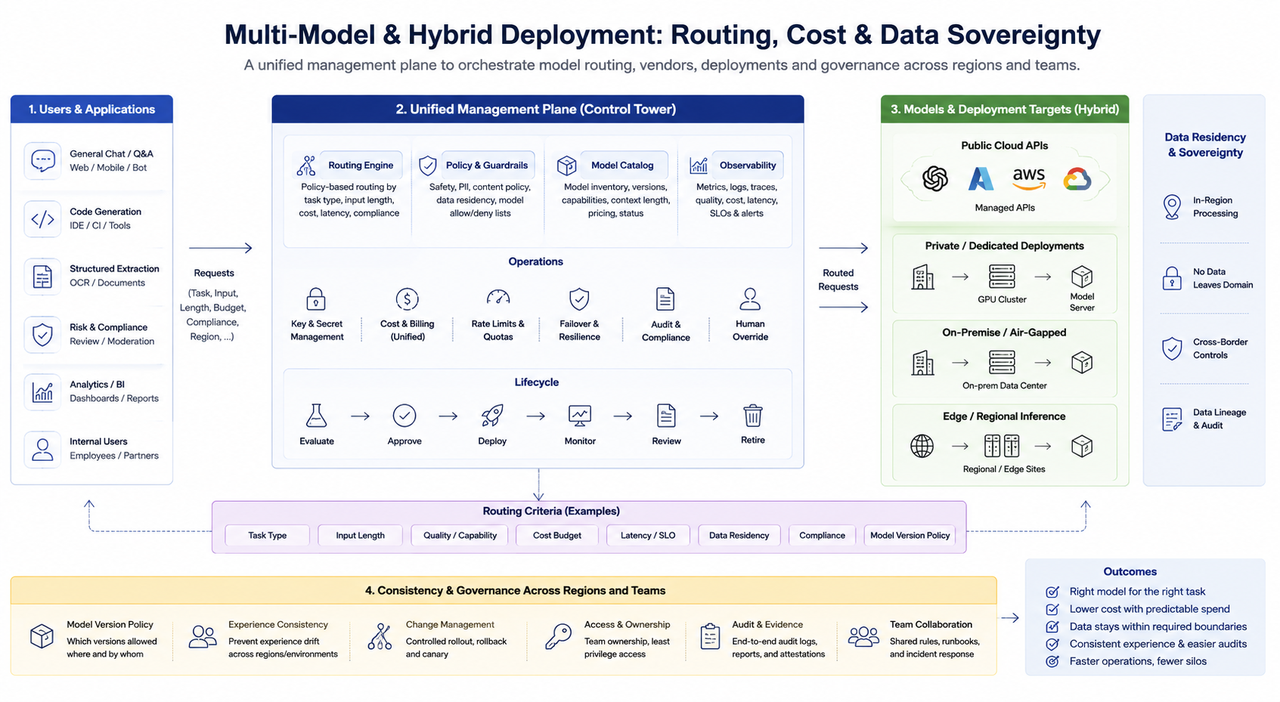
Em ambientes corporativos, é comum a coexistência de múltiplos modelos: tarefas como conversação geral, código, extração estruturada e revisão de controle de risco não são adequadas a um único modelo ou estratégia de parâmetros. Os principais desafios de engenharia em ambientes multi-modelo incluem:
-
Estratégia de roteamento: Seleção de modelos conforme tipo de tarefa, tamanho do input, restrições de custo e compliance; exige estratégias padrão interpretáveis e possibilidade de ajustes manuais.
-
Mix de fornecedores: APIs de nuvem pública, deploys locais e clusters dedicados podem coexistir; gestão unificada de chaves, padrões de cobrança e failover são essenciais para evitar que “vários fornecedores se tornem silos isolados”.
-
Nuvem híbrida e residência de dados: Operações financeiras, governamentais e internacionais frequentemente exigem que dados permaneçam em determinado domínio ou jurisdição; o deploy de inferência define a arquitetura de rede e o posicionamento do cache, interagindo com infraestrutura como data centers, energia e redes regionais.
-
Governança de consistência: Políticas claras são necessárias para definir se o mesmo negócio em diferentes regiões pode usar versões distintas de modelos; do contrário, surgem desvios de experiência e dificuldades de auditoria.
Na prática organizacional, a dificuldade dos sistemas multi-modelo geralmente não está no “número de modelos”, mas na ausência de uma gestão unificada. Quando regras de roteamento, chaves, monitoramento e processos de liberação estão dispersos, os custos de troubleshooting e compliance crescem rapidamente.
Agente: Orquestração, Limites de Ferramentas e Auditabilidade
Agentes expandem a inferência para tarefas de múltiplas etapas: planejamento, uso de ferramentas, operações de memória e geração de próximas ações. Para sistemas corporativos, isso significa que o risco sai do “texto de saída” e passa a impactar sistemas externos de forma executável.
Principais áreas de atenção na prática:
-
Whitelist de ferramentas e menor privilégio: Cada ferramenta precisa de escopos de permissão bem definidos (bancos de dados somente leitura, APIs restritas, caminhos limitados etc.) para evitar “invocação onipotente de ferramentas”.
-
Colaboração humano-máquina e pontos de confirmação: Para ações de alto risco como transferência de fundos, mudanças de permissão ou exportação em massa de dados, é obrigatório impor fluxos de confirmação ou aprovação, em vez de automação total.
-
Estado de sessão e limites de memória: Memória de longo prazo envolve privacidade e ciclos de retenção; contexto de curto prazo impacta custos e estratégias de truncamento. Políticas de tierização e limpeza de dados devem estar alinhadas ao compliance.
-
Trilhas auditáveis: Registrar “quando o modelo, com base em qual contexto, invocou quais ferramentas e o que foi retornado”; revisões de incidentes e investigações regulatórias dependem disso, não apenas da resposta final.
-
Sandbox e isolamento: Execução de código e carregamento de plugins exigem ambientes isolados para evitar que injeção de prompt evolua para ataques em nível de execução.
Agentes agregam valor pela automação, mas só quando os limites são claros. Se não houver clareza, a complexidade do sistema cresce exponencialmente e os custos operacionais e legais podem sair do controle antes que qualquer benefício de negócio seja percebido.
Segurança e Compliance: O “Mínimo Essencial” para Lançamento e Operação
Os requisitos de compliance variam conforme o setor, mas sistemas corporativos em produção devem cumprir ao menos o seguinte “mínimo essencial”, expandindo conforme necessário para atender demandas regulatórias.
-
Identidade e acesso: Contas de serviço, contas de usuário, rotação de chaves de API e princípio do menor privilégio; distinguir entre credenciais de “desenvolvimento/teste” e “produção”.
-
Dados e privacidade: Mascaramento de campos sensíveis, logs mascarados, separação de dados de treinamento e inferência; definir e manter acordos de processamento de dados com fornecedores de modelos de terceiros.
-
Cadeia de suprimentos de modelos: Rastreabilidade das fontes dos modelos, hashes de versões, dependências e imagens de contêiner; impedir que “pesos desconhecidos” entrem no ambiente de produção.
-
Segurança de conteúdo e prevenção de abuso
-
Aplicar filtragem de políticas em entradas/saídas quando necessário; implementar limitação de taxa e detecção de anomalias para chamadas automáticas em lote.
-
Resposta a incidentes: Rollback de modelo, troca de roteamento, revogação de chaves, procedimentos de notificação ao cliente; definir claramente responsáveis e caminhos de escalonamento.
Essas capacidades não substituem a defesa em profundidade da equipe de segurança, mas são fundamentais para integrar serviços de IA ao framework de gestão de riscos da empresa, evitando que permaneçam como “exceções de inovação” a longo prazo.
Conclusão
A vantagem competitiva em IA corporativa está migrando de “integrar o modelo mais recente” para “operar múltiplos modelos e agentes com custos controlados e limites seguros”. Isso exige o fortalecimento tanto do stack de engenharia quanto de governança: roteamento e liberação, observabilidade e gestão de custos, permissões de ferramentas e trilhas de auditoria devem ser considerados essenciais de produção, no mesmo nível dos próprios modelos.









