O avanço acelerado dos modelos de IA está impulsionando uma forte demanda global por GPU. Com a expansão dos modelos de linguagem de grande porte (LLMs), Agentes de IA e aplicações de automação, as plataformas tradicionais de IA em nuvem centralizadas enfrentam custos elevados, concentração de recursos e limitações de escalabilidade. Nesse contexto, redes descentralizadas de GPU despontam como um dos principais caminhos para a infraestrutura de IA no Web3.
A Dolphin Network é uma rede de inferência de IA criada para responder a essa demanda. Seu principal objetivo é reunir GPUs distribuídas globalmente em uma infraestrutura aberta de IA, coordenando desenvolvedores, nós de GPU e a rede por meio do mecanismo de incentivo POD.
Qual é a estrutura central da Dolphin Network?
A arquitetura central da Dolphin Network é composta por três elementos: solicitantes de inferência de IA, a rede de nós de GPU e um mecanismo de verificação e coordenação.
Desenvolvedores ou aplicações podem submeter solicitações de inferência de IA — como geração de texto, inferência de chat, chamada de modelos ou tarefas de Agente de IA — para a rede. O sistema distribui essas solicitações dinamicamente para os nós apropriados, considerando o status dos nós de GPU, as exigências das tarefas e a disponibilidade de recursos.
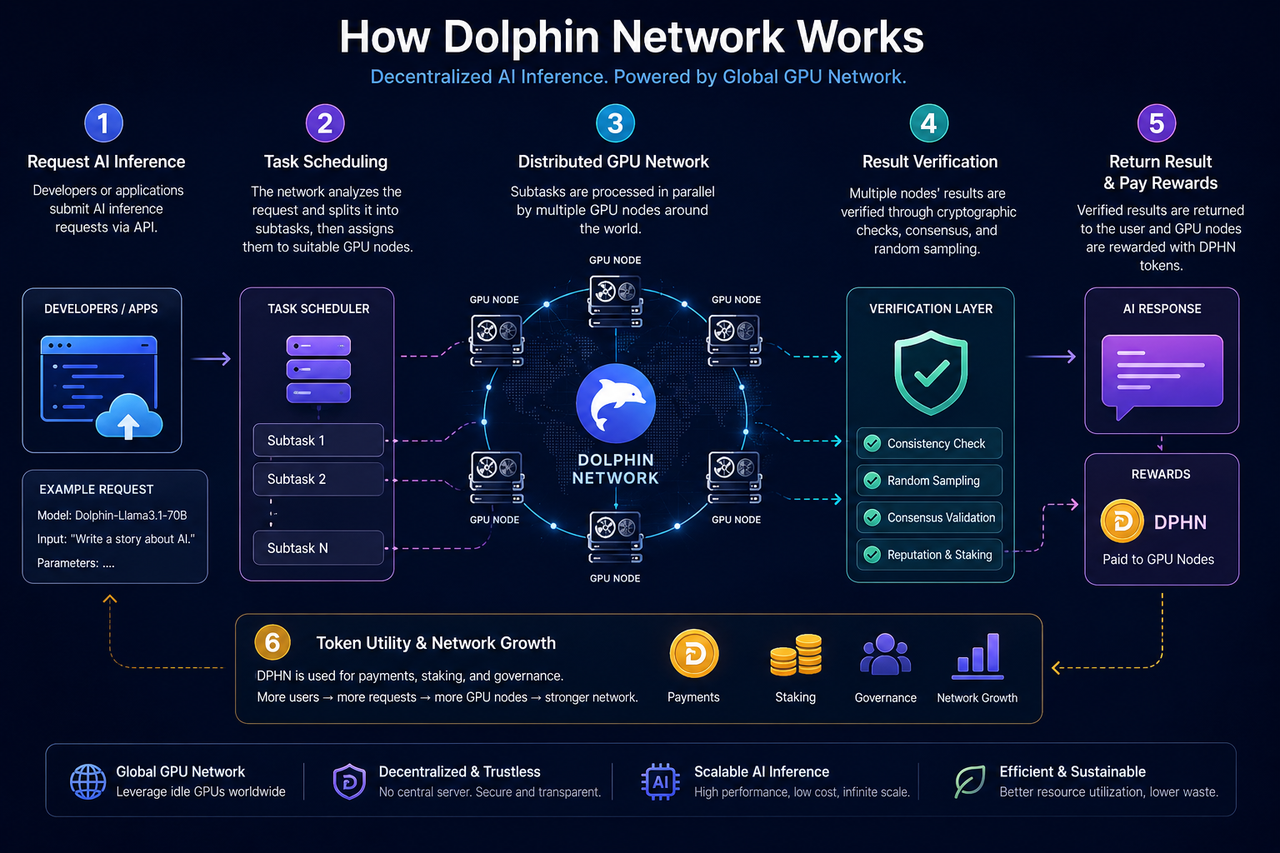
Os nós de GPU são disponibilizados por usuários ao redor do mundo. Qualquer participante pode conectar GPUs ociosas, executar tarefas de inferência localmente e receber recompensas em tokens conforme sua contribuição.
Para garantir a integridade dos resultados, a Dolphin utiliza mecanismos de verificação e incentivos econômicos para coordenar o comportamento dos nós, incluindo amostragem aleatória, revisão de tarefas e sistemas de stake.
Como as solicitações de inferência de IA entram na rede?
Quando um desenvolvedor acessa a Dolphin Network, as solicitações são direcionadas inicialmente à camada de agendamento de tarefas.
Essa camada avalia o tipo de tarefa, as necessidades de GPU e os recursos do modelo. Como diferentes modelos de IA podem exigir configurações de memória, velocidades de inferência e capacidade computacional variadas, a rede faz o pareamento dinâmico das solicitações com os nós disponíveis.
Em plataformas de IA em nuvem centralizadas, esse processo ocorre em um único data center. Na Dolphin, as tarefas são distribuídas por uma rede descentralizada de nós de GPU.
Algumas tarefas podem ser divididas em solicitações de inferência menores, aumentando a eficiência geral e a concorrência da rede.
Como os nós de GPU processam tarefas de inferência de IA?
Os nós de GPU representam o principal recurso computacional da Dolphin Network.
Operadores de nós instalam o software específico e permitem que o sistema utilize as GPUs locais para executar tarefas de inferência de IA. Ao receber uma tarefa, o nó baixa o modelo ou os parâmetros necessários e realiza o processamento localmente.
Depois de concluir o trabalho, o nó envia os resultados da inferência para a rede e aguarda a verificação para confirmar a validade. Apenas tarefas aprovadas na verificação recebem recompensas em tokens.
Essa abordagem é diferente da mineração tradicional com GPU. Enquanto as redes PoW focam em cálculos de hash, os nós de GPU da Dolphin realizam tarefas reais de inferência de IA, aproximando-se de um “mercado de poder de hash disponível”.
Como a Dolphin verifica os resultados de inferência de IA?
A inferência de IA não pode ser validada por fórmulas matemáticas simples, como ocorre em transações de blockchain. Por isso, a Dolphin utiliza mecanismos adicionais para evitar que nós submetam resultados incorretos.
Uma prática comum é a amostragem aleatória — selecionar tarefas aleatórias para revisão e verificar a consistência dos resultados entre múltiplos nós. O envio frequente de dados anormais pode reduzir a reputação do nó ou impedir que ele receba recompensas.
Algumas redes descentralizadas de IA também utilizam stake. Para participar, os nós precisam fazer stake de tokens e, em caso de comportamento malicioso, podem sofrer penalidades nos ativos em stake.
Esses incentivos econômicos buscam alinhar o comportamento dos nós e fortalecer a credibilidade da rede.
Como a Dolphin se diferencia da inferência de IA em nuvem tradicional?
Plataformas tradicionais de IA em nuvem dependem de grandes data centers centralizados — um único agente controla clusters de GPU, implantação de modelos e serviços de API.
A Dolphin adota uma arquitetura aberta de rede de GPU. Os nós de GPU são fornecidos por usuários do mundo todo, permitindo que desenvolvedores acessem serviços de inferência de IA em um ambiente aberto, reduzindo a dependência de um único provedor.
A Dolphin também prioriza modelos de IA abertos e o compartilhamento de recursos. Algumas redes permitem a implantação de modelos open-source, regras de sistema personalizadas e cenários abertos de Agentes de IA.
No entanto, redes de IA distribuídas enfrentam desafios como estabilidade, latência de rede e variação na qualidade dos nós, estando ainda em fase inicial de desenvolvimento.
Quais desafios a Dolphin Network enfrenta?
Redes descentralizadas de inferência de IA promovem abertura e compartilhamento de recursos, mas enfrentam desafios práticos.
O desempenho dos nós de GPU é muito variável. Diferenças em memória, largura de banda e capacidade de inferência afetam a estabilidade da rede.
A validação dos resultados de inferência de IA é complexa. Ao contrário das transações em blockchain, os resultados de IA são probabilísticos, elevando o custo de verificação.
Com o crescimento dos modelos de IA, o agendamento eficiente de grandes clusters de GPU em ambientes distribuídos se torna um desafio central para projetos de IA DePIN.
A incerteza regulatória é outro ponto. Modelos de IA abertos podem gerar preocupações com dados, direitos autorais e geração de conteúdo, exigindo que as redes de infraestrutura de IA administrem riscos regulatórios de longo prazo.
Resumo
A Dolphin Network é uma rede descentralizada de inferência de IA que une IA e DePIN, com o objetivo de construir uma infraestrutura aberta de IA baseada em nós de GPU globais. A rede coordena desenvolvedores e nós de GPU por meio de agendamento de tarefas, inferência distribuída, verificação aleatória e o mecanismo de incentivo DPHN.
Em relação às plataformas tradicionais de IA em nuvem centralizadas, a Dolphin destaca-se pela abertura, compartilhamento de recursos e resistência à censura, posicionando-se como referência para infraestrutura de IA no Web3.
Perguntas Frequentes
Como a Dolphin utiliza os nós de GPU?
Holders de GPU podem implantar nós e disponibilizar GPUs ociosas para executar tarefas de inferência de IA e receber recompensas em DPHN.
Quais as etapas do processo de inferência de IA na Dolphin?
O fluxo principal inclui envio de tarefas, agendamento dos nós, execução da inferência na GPU, verificação dos resultados e distribuição das recompensas.
Por que a Dolphin é considerada um projeto DePIN?
Seus recursos principais são GPUs reais, e a infraestrutura distribuída é coordenada por incentivos baseados em tokens.
Como a Dolphin se diferencia das plataformas tradicionais de IA em nuvem?
Plataformas tradicionais de IA em nuvem dependem de data centers centralizados; a Dolphin utiliza uma rede aberta de GPU para oferecer serviços de inferência de IA distribuída.
Qual a função do DPHN na rede?
O DPHN é utilizado para pagamentos de inferência de IA, recompensas de nós, stake e incentivo econômico dentro da rede.









