À medida que as cargas de trabalho de inferência evoluem dos clusters de teste para aplicações empresariais reais, a solução ótima por defeito deixa de ser "tudo centralizado em centros de dados de escala ultra-grande". Este artigo explora a lógica estratificada dos nodos edge, centros de dados regionais e clusters centrais, considerando latência, largura de banda, disponibilidade e conformidade. Explica pontos-chave na divisão de tarefas, limites de dados e governança operacional em topologias híbridas, e apresenta uma visão comparativa face à cadeia de infraestrutura de IA mais ampla.
As narrativas públicas tendem a equiparar o poder de hash de IA a "centros de dados ultra-grandes e GPUs topo de gama". Esta definição aplica-se, em geral, ao treino e a cenários de inferência centralizada. Infraestrutura de IA caracteriza-se por pedidos de inferência amplamente distribuídos, sensíveis à latência e que exigem permanência dos dados no domínio, onde interrupções de rede ou congestionamento de pico são intoleráveis. Nestes casos, a topologia de inferência torna-se um desafio de infraestrutura: o poder de hash precisa de estar disponível e situado na "localização geográfica e camada de rede adequadas".
Se a infraestrutura de IA for vista como uma cadeia contínua, do nível do chip até aos serviços e governança, este artigo foca-se na topologia e formas de implementação: como distribuir computação e dados entre camadas edge, regionais e centrais para equilibrar latência, custo, disponibilidade e conformidade. Temas a montante, como energia, packaging e HBM, são mais apropriados para o lado da oferta, enquanto routing multi-modelo e governança de agentes a nível empresarial complementam as operações de produção.
Porque abordar a "topologia de inferência distribuída"
A inferência centralizada proporciona operações unificadas, escalabilidade flexível e elevada utilização de recursos. Contudo, quando o negócio apresenta alguma das seguintes características, as decisões de topologia afetam significativamente a experiência e o custo:
-
Restrições severas de latência: Controlo industrial, interação em tempo real, ligações áudio/vídeo e retalho offline são sensíveis à latência de cauda; trajetos de retorno demasiado extensos amplificam o jitter.
-
Soberania e residência de dados: Informação pessoal, transações financeiras, serviços governamentais e saúde exigem frequentemente que os dados permaneçam no domínio, dentro das fronteiras ou em regiões designadas.
-
Largura de banda de retorno e custos: Endpoints massivos enviam continuamente dados brutos para inferência central, tornando taxas de backbone e egressão potenciais principais fatores de custo.
-
Disponibilidade e resiliência: Falhas de rede de área alargada, flutuações de DNS ou congestionamento entre regiões tornam arquiteturas puramente centrais mais propensas a riscos de cascata de "indisponibilidade total".
-
Rede offline ou instável: Ambientes como minas, navios e locais de fabrico exigem capacidade operacional local, em vez de dependência de conectividade online em tempo real.
Estes desafios não se resolvem com "modelos centrais mais potentes", pois os problemas centrais residem na distância física, trajetos de rede e limites de políticas — não no pico de poder de hash de uma única inferência.
Implementação em camadas: soluções das camadas edge, regionais e centrais
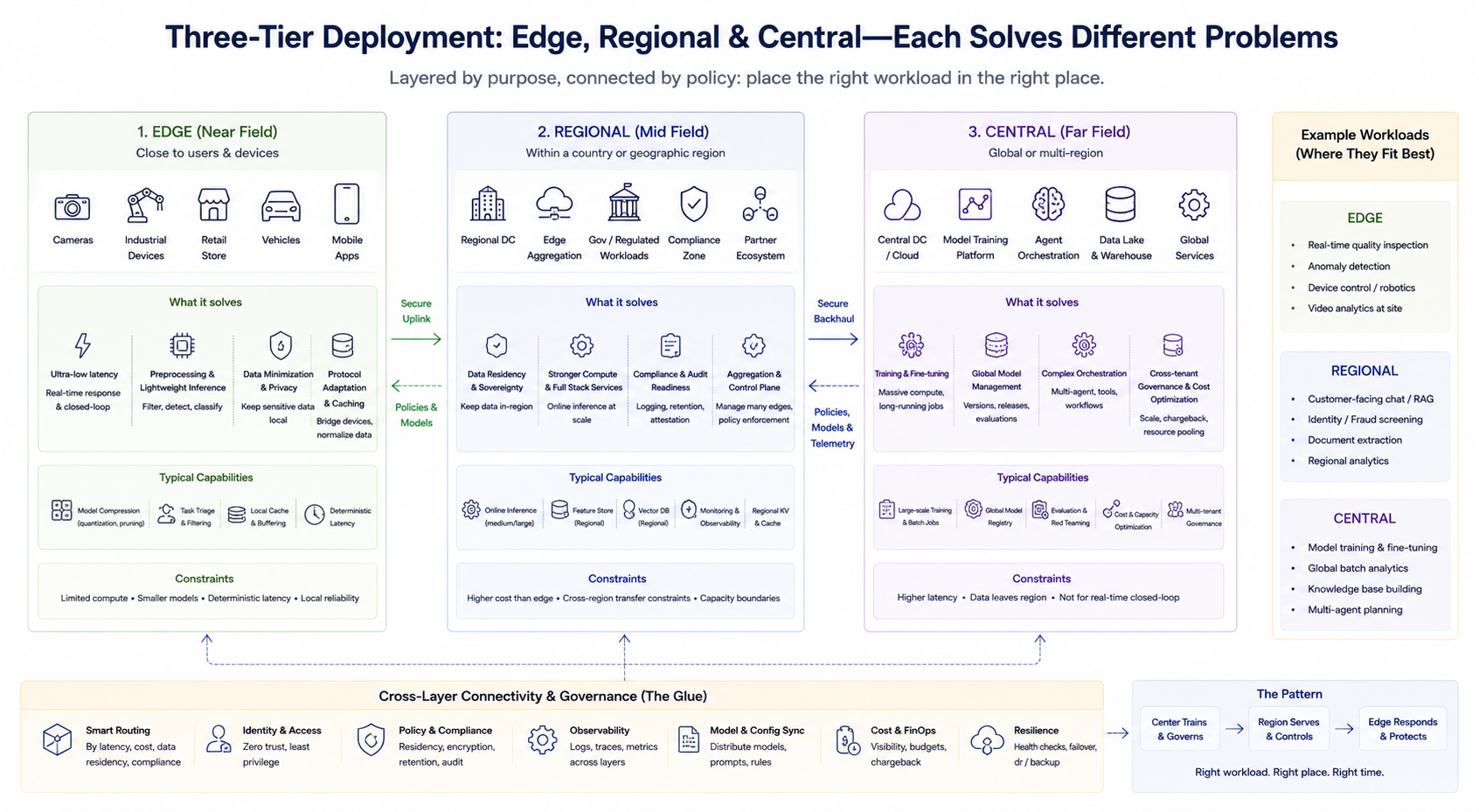
A engenharia típica não se baseia numa escolha binária, mas numa combinação em camadas. Uma estrutura simplificada clarifica as responsabilidades de cada camada (a nomenclatura pode variar consoante o fornecedor):
Camada edge (campo próximo)
Situada perto dos utilizadores ou dispositivos, esta camada lida com pré-processamento de baixa latência, inferência leve, cache e adaptação de protocolos. É ideal para loops fechados em tempo real e para minimizar uploads de dados sensíveis. O poder de hash edge é limitado, pelo que se privilegia compressão de modelos, poda de tarefas e latência determinística.
Camada regional (campo intermédio)
Oferece maior poder de hash e um stack de serviços mais completo em países ou regiões geográficas específicas, satisfazendo requisitos de residência de dados, auditoria de conformidade e necessidades de inferência agregada de média escala. Serve também como plano de agregação e controlo para vários nodos edge.
Camada central (campo distante)
Responsável por treino, processamento em lote de grande escala, gestão global de modelos, orquestração complexa de agentes, governança unificada entre tenants e otimização de custos. Adequada para cargas de trabalho menos sensíveis à latência, mas que requerem elevado poder de hash e agregação de dados.
Estas três camadas não são hierarquias rígidas, mas dividem-se conforme as tarefas do negócio. As empresas podem operar simultaneamente treino central, inferência online regional e deteção edge em tempo real, encaminhando pedidos para a camada adequada conforme as estratégias de routing.
Divisão de tarefas: o que permanece na edge, o que retorna ao centro
Os princípios de divisão baseiam-se em quatro eixos: minimização de dados, orçamento de latência, complexidade de modelos e frequência de atualização.
Tarefas adequadas à edge (assumindo requisitos de poder de hash cumpridos):
-
Extração de características em tempo real, deteção de objetos, verificações de qualidade e outros loops fechados de baixa latência
-
Inferência leve após dessensibilização local (por exemplo, upload apenas de vetores de características em vez de media bruta)
-
Estratégias de inferência fallback e cache hit em redes instáveis
Tarefas adequadas ao centro ou região:
-
Workflows de agentes que requerem contexto amplo, modelos robustos, toolchains complexos ou orquestração multi-sistema
-
Inferência analítica que exige agregação de dados entre departamentos
-
Chamadas sensíveis que requerem auditoria centralizada e gestão unificada de chaves
Erros comuns incluem forçar grandes modelos com contexto longo para a edge, levando a OOM, ou enviar loops fechados de baixa latência para o centro, causando perturbações na linha de produção. O objetivo da topologia não é "quanto mais edge, melhor", mas colocar a carga de trabalho certa no local certo, sob as restrições existentes.
Os requisitos de soberania de dados alteram diretamente as formas de implementação de inferência. Modelos podem ser descarregados localmente, mas logs, caches, índices de vetores e rastreios de chamadas podem representar riscos de conformidade. Na prática, as questões-chave são:
-
Que dados devem ser armazenados e processados na camada edge ou regional
-
Que metadados podem sair da região ou ir para a cloud, e se é necessária anonimização e definição de períodos de retenção
-
Se é permitido o uso entre regiões de versões distintas de modelos e fornecedores (para evitar "deriva de conformidade")
-
Se, durante auditoria e forense, a saída pode ser reconstruída como "gerada num determinado local, hora e com base em fragmentos de dados específicos"
As respostas a estas questões determinam frequentemente se um sistema pode entrar em produção, mais do que "se o modelo é open source". Ou seja, a conformidade não é um extra para inferência edge, mas um requisito de entrada para o design de topologia.
Rede, energia e operações: custos reais da implementação distribuída
A inferência distribuída implica custos sistémicos que devem ser avaliados explicitamente no planeamento:
-
Rede: À medida que aumentam nodos edge e regionais, a gestão de certificados, linhas dedicadas / SD‑WAN, DNS e complexidade de scheduling de tráfego aumentam. A latência de cauda é mais difícil de controlar em condições multipath.
-
Energia e centros de dados: Os sites edge são dispersos, e a eficiência energética e condições de cooling por unidade de poder de hash podem ser inferiores aos grandes centros de dados; os centros regionais são intermédios. O ritmo de entrega upstream de energia e racks condiciona a expansão, mas a restrição passa de "campus único" para "multi-ponto paralelo".
-
Operações e consistência de versões: Quando modelos, prompts, estratégias de routing e índices são libertados em múltiplos pontos, pode ocorrer deriva de versões. São necessários pipelines de libertação unificados, estratégias de rollback e health checks, caso contrário os custos de troubleshooting anulam rapidamente os ganhos de latência da edge.
-
Expansão do âmbito de segurança: Mais nodos significam mais certificados, mais pontos de entrada e mais media de armazenamento local. A segurança física e ciclos de patch na edge são frequentemente mais frágeis do que nos centros de dados centrais, exigindo estratégias de privilégio mínimo e controlo remoto direcionadas.
Portanto, a topologia distribuída não é apenas "empurrar poder de hash para fora", mas deslocar parte da complexidade operacional e de governança para junto do local de negócio. Se as capacidades organizacionais e ferramentas de plataforma não acompanham, as vantagens da topologia são difíceis de concretizar.
As soluções maduras adotam arquiteturas híbridas: o centro gere treino, políticas globais e cargas pesadas; a região gere serviços online em zonas de conformidade; a edge assegura baixa latência e resiliência local. Os padrões de engenharia incluem:
-
Cache em camadas e reutilização de resultados: A edge serve pedidos de alta frequência, e misses são enviados ao centro. Chaves de cache, TTL e políticas de dados sensíveis devem ser definidas.
-
Divisão de modelos e front-end de modelos pequenos: A edge executa modelos pequenos de deteção ou classificação, o centro executa fusão de modelos grandes e geração de interpretações (avaliado por cenário).
-
Retorno e agregação assíncrona: A edge toma decisões em tempo real e retorna amostras dessensibilizadas ou métricas de forma assíncrona para iteração de modelos e monitorização.
-
Plano de controlo unificado: Routing, quotas, monitorização e gestão de chaves são centralizados sempre que possível, com execução descentralizada, para evitar o risco de "cada edge como ilha isolada".
O sucesso das arquiteturas híbridas depende de um plano de controlo unificado e de um plano de execução em camadas — não simplesmente do aumento do número de nodos.
Conclusão
A discussão sobre inferência edge e distribuída não se resume a um "slogan de descentralização", mas a trade-offs de engenharia entre latência, largura de banda, conformidade e custo operacional. À medida que o negócio passa de demo a escala, as escolhas de topologia moldam modelos, arquiteturas de rede e processos organizacionais. Ignorar esta camada pode resultar em poder de hash central robusto, mas instabilidade persistente na linha da frente.








