51,2 万 строк кода, 1906 файлов, 59,8 МБ source map. В ночь на 31 марта Чафан Шоу из Solayer Labs обнаружил, что флагманский продукт Anthropic Claude Code раскрыл полный исходный код в публичном репозитории npm. В течение нескольких часов код отзеркалили в GitHub, а число fork превысило 41 000.
Это не первая ошибка Anthropic такого рода. Когда в феврале 2025 года Claude Code впервые выпустили, утечка того же source map уже происходила один раз. Версия на этот раз — v2.1.88, причина утечки та же: сборщик Bun по умолчанию генерирует source map, а в .npmignore забыли указать этот файл.
Большинство публикаций в обзоре утечки смакуют пасхалки, например виртуальную систему домашних питомцев и «режим под прикрытием», позволяющий Claude анонимно отправлять код в open source. Но по-настоящему интересный вопрос для разборки — почему один и тот же Claude-модель в веб-версии и в Claude Code ведёт себя настолько по-разному? Чем именно занимается 512 000 строк кода?
Модель — лишь верхушка айсберга
Ответ спрятан в структуре кода. По результатам реверс-анализа исходников утечки сообществом GitHub, из 512 000 строк TypeScript код, который напрямую отвечает за вызов AI-модели, составляет лишь около 8000 строк, то есть 1,6% от общего объёма.
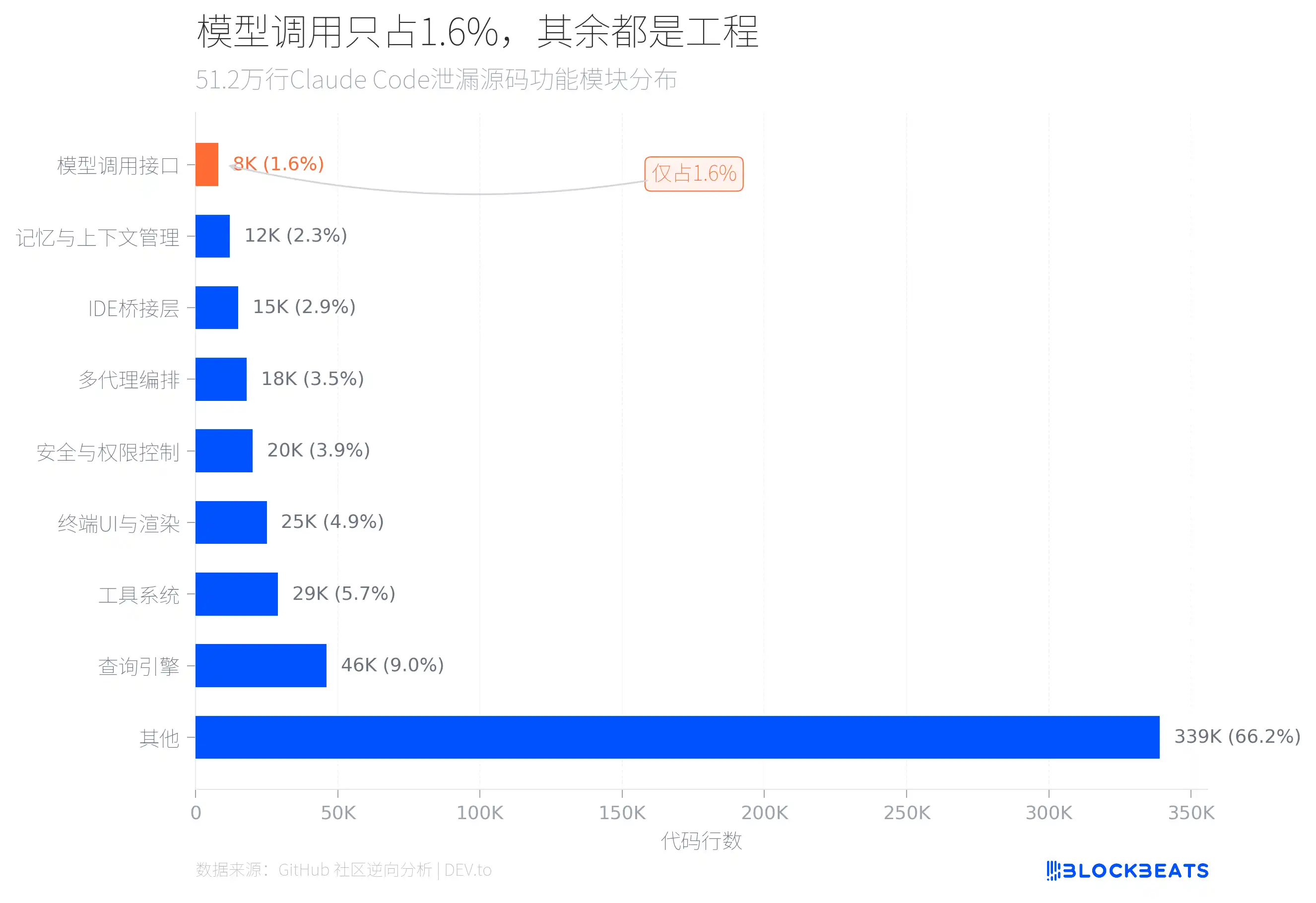
Чем заняты оставшиеся 98,4%? Самые крупные два модуля — поисковый движок (46 000 строк) и система инструментов (29 000 строк). Поисковый движок обрабатывает вызовы LLM API, потоковый вывод, оркестрацию кэша и управление многошаговыми диалогами. Система инструментов определяет около 40 встроенных инструментов и 50 слэш-команд, формируя набор, похожий на плагинную архитектуру: у каждого инструмента есть независимый контроль прав.
Кроме того, есть 25 000 строк кода отрисовки терминального UI (один из файлов, print.ts, достигает 5594 строк, а один-единственный файл содержит функцию длиной 3167 строк), 20 000 строк безопасности и контроля прав (включая 23 пункта нумерованных проверок безопасности Bash и 18 отключённых встроенных команд Zsh), а также 18 000 строк системы оркестрации многопрокси.
Исследователь машинного обучения Себастьян Расчка после анализа утёкшего кода отметил, что Claude Code сильнее веб-версии при том же самом модели не потому, что «сама модель» лучше, а потому что вокруг модели выстроен программный каркас: загрузка контекста репозитория, планирование специализированных инструментов, стратегии кэширования и кооперация с дочерними агентами. Он даже считает, что если натянуть ту же инженерную архитектуру на DeepSeek или Kimi и другие модели, можно получить почти такое же улучшение в возможностях программирования.
Понять разницу помогает наглядное сравнение. Если вы в ChatGPT или веб-версии Claude зададите вопрос, модель обработает его и вернёт ответ — на этом диалог заканчивается, и ничего не остаётся. Но подход Claude Code совсем другой: при запуске он сначала читает файлы вашего проекта, понимает структуру кодовой базы и запоминает ваши предпочтения вроде «не подменяй базу данных моками в тестах». Он может напрямую выполнять команды в вашем терминале, редактировать файлы, запускать тесты. Когда задача становится сложной, он разбивает её на несколько подзадач и распределяет их параллельно между разными дочерними агентами. Другими словами, веб-AI — это окно для вопрос-ответа, а Claude Code — это соавтор, живущий у вас на компьютере.
Кто-то сравнил эту архитектуру с операционной системой: 42 встроенных инструмента — это системные вызовы, система прав — это управление пользователями, протокол MCP — это драйверы устройств, а оркестрация дочерних агентов — диспетчеризация процессов. Каждый инструмент при поставке по умолчанию помечен как «небезопасный, с записью», если только разработчик не объявил его безопасным намеренно. Инструмент для редактирования файлов принудительно проверяет, читали ли вы сначала этот файл: если нет — изменить нельзя. Это не «примочка» к чат-боту с несколькими инструментами, а среда выполнения с ядром на LLM и полноценными механизмами безопасности.
Это означает одну вещь: конкурентные барьеры AI-продукта могут быть не на уровне моделей, а на уровне инженерии.
Каждый пробой кэша — стоимость растёт в 10 раз
В утёкшем коде есть файл promptCacheBreakDetection.ts — он отслеживает 14 векторов, которые могут привести к невалидности prompt cache. Почему инженеры Anthropic тратят столько усилий, чтобы предотвращать пробои кэша?
Посмотрите на официальное ценообразование Anthropic — и всё станет ясно. Например, для Claude Opus 4.6 стандартная цена входа — 5 долларов за миллион token, но при попадании в кэш цена чтения всего 0,5 доллара — на 90% дешевле. И наоборот: каждый раз, когда кэш «пробивается», стоимость вывода увеличивается в 10 раз.
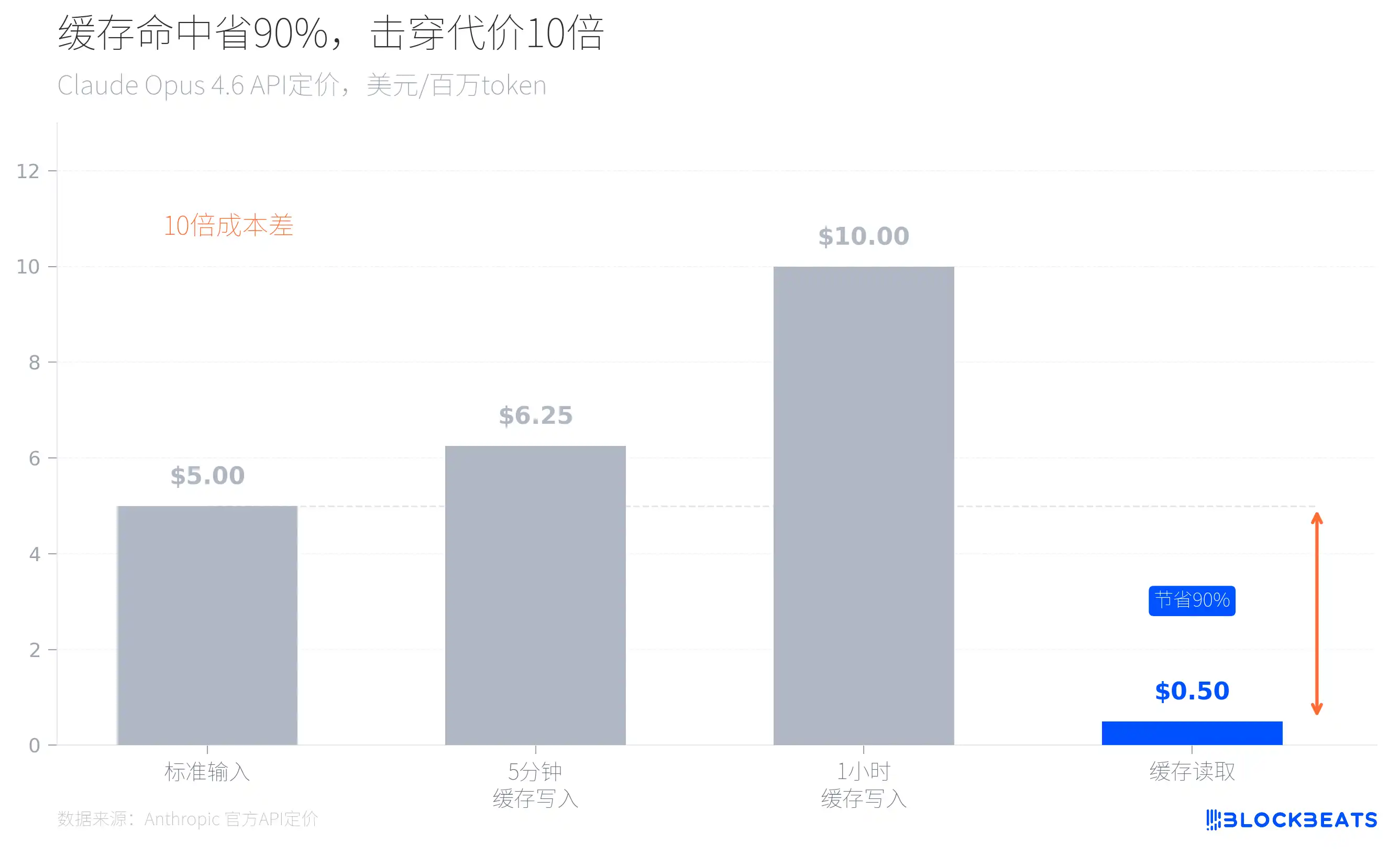
Это объясняет множество архитектурных решений, которые в утёкшем коде выглядят как «чрезмерная продуманность». Когда Claude Code запускается, он загружает текущую ветку git, записи последних commit и файл CLAUDE.md как контекст; эти статические данные кэшируются глобально, а динамический контент отделяется пограничными маркерами, чтобы каждый диалог не обрабатывал уже имеющийся контекст заново. В коде также есть механизм под названием sticky latches, который предотвращает переключение режимов, разрушающее уже созданный кэш. Дочерние агенты спроектированы так, чтобы переиспользовать кэш родительского процесса, а не заново строить свои контекстные окна.
Есть один деталируемый момент. Пользователи AI-инструментов для программирования знают: чем длиннее диалог, тем медленнее ответ AI, потому что на каждом шаге диалога нужно снова отправлять в модель всю предыдущую историю. Обычный подход — удалять старые сообщения, чтобы освобождать место, но проблема в том, что удаление любой записи ломает непрерывность кэша, из-за чего всю историю диалога приходится обрабатывать заново; в итоге растут и задержка, и расходы.
В утёкшем коде есть механизм cache_edits: вместо того чтобы реально удалять сообщения, в API-слое старым сообщениям ставят пометку «пропустить» (“skip”). Модель не видит эти сообщения, но непрерывность кэша не нарушается. Это означает: для длительного диалога, который длится часами, после очистки сотен старых сообщений следующая реакция будет почти такой же быстрой, как и первая. Для обычных пользователей это и есть скрытый ответ на вопрос «почему Claude Code поддерживает бесконечно длинные диалоги и при этом не замедляется».
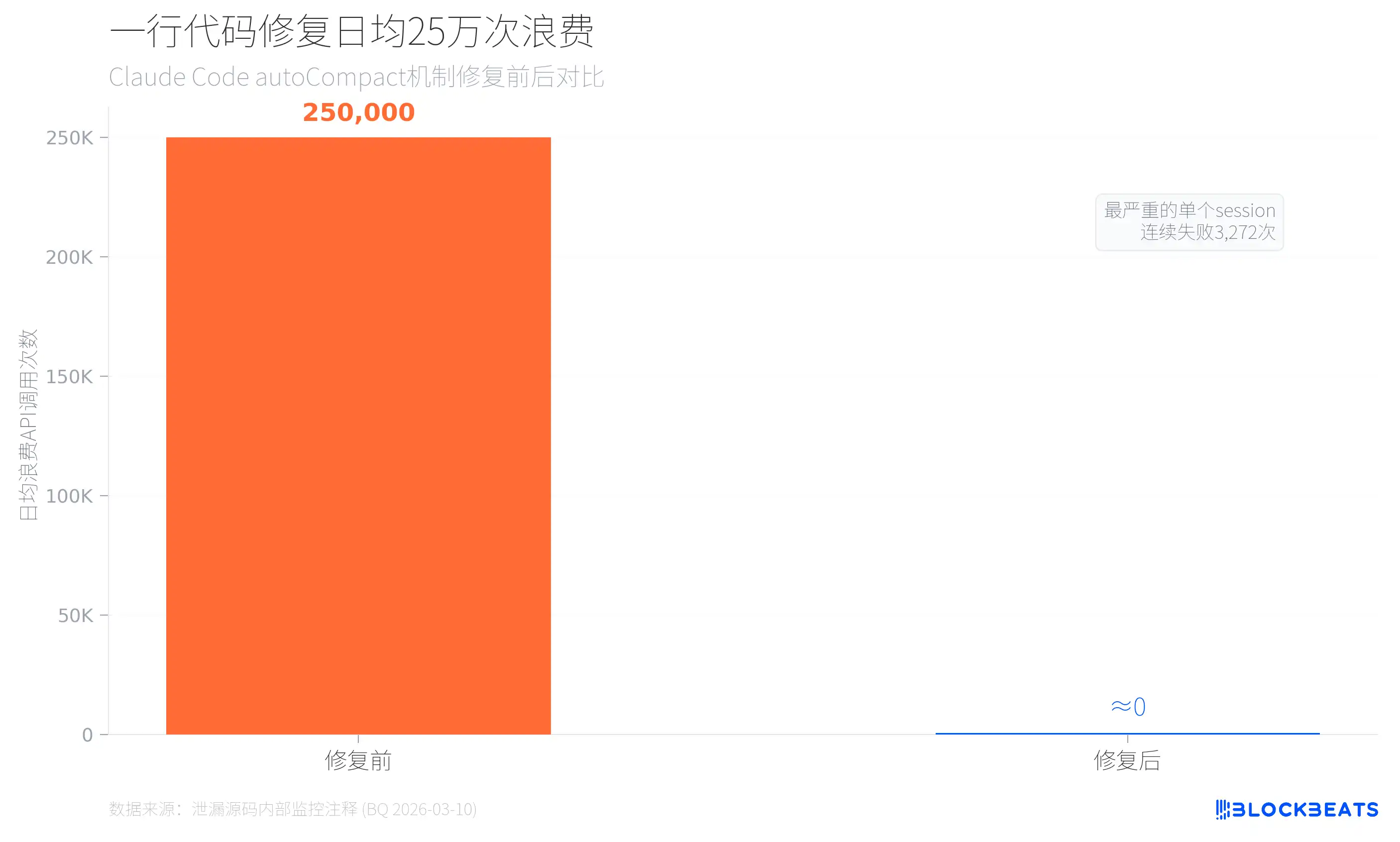
Согласно данным внутреннего мониторинга в утечке (из комментариев в коде autoCompact.ts, дата помечена как 10 марта 2026), до введения лимита на неудачные автоматические сжатия Claude Code ежедневно тратил примерно 250 000 раз вызовов API впустую. У 1279 пользовательских сессий было 50+ подряд идущих неудач автоматического сжатия, а в самом тяжёлом случае одна сессия провалилась 3272 раза подряд. Исправление было простым: добавили одну строку ограничения — MAX_CONSECUTIVE_AUTOCOMPACT_FAILURES = 3.
Так что для AI-продуктов расходы на вывод модели могут быть не самым дорогим слоем, а провалы в управлении кэшем — именно ими.
44 переключателя — в одном и том же направлении
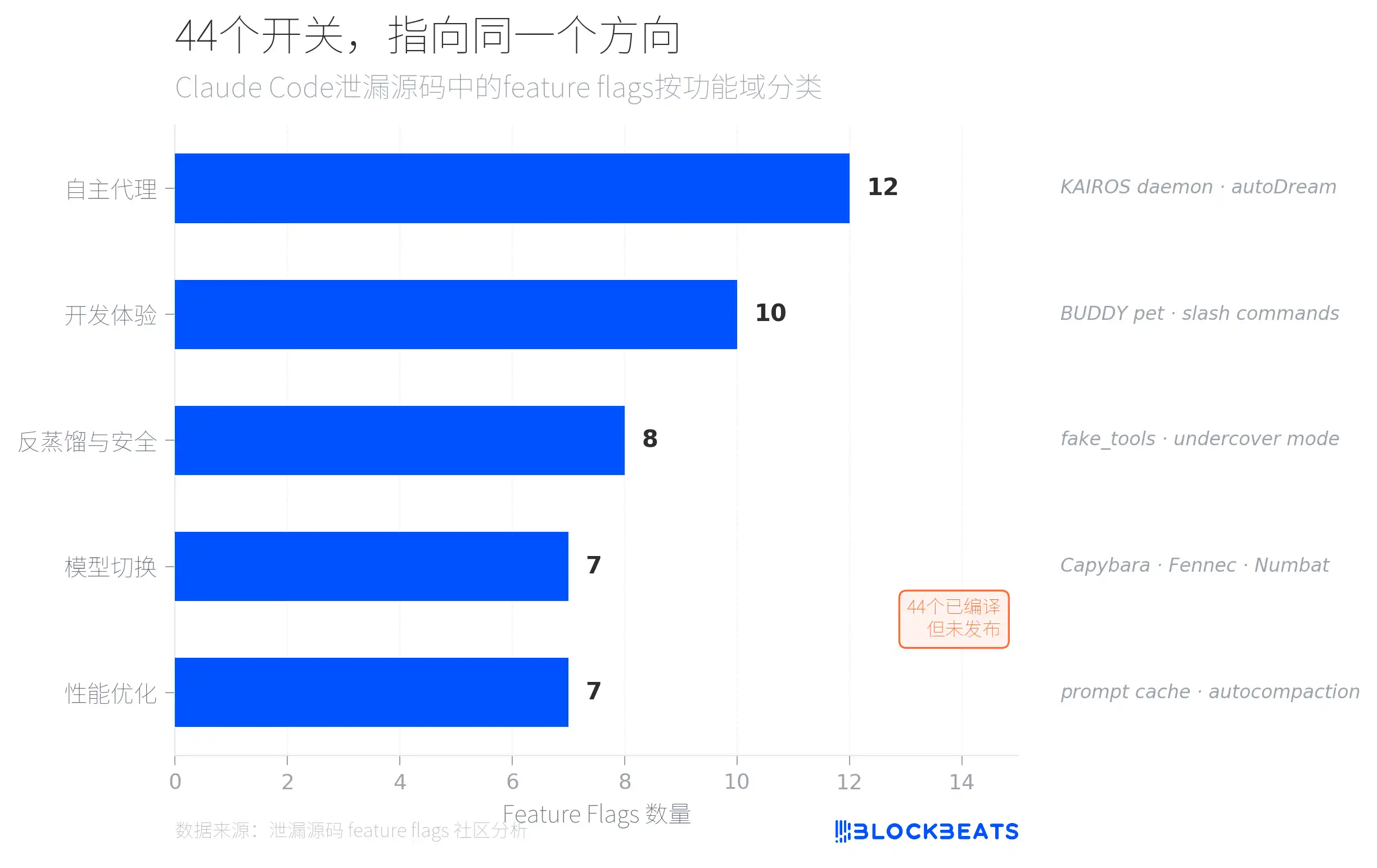
В утёкшем коде спрятаны 44 feature flags — уже скомпилированные переключатели функций, но ещё не вынесенные наружу. По анализу сообщества, эти флаги сгруппированы по функциональным областям в пять категорий, и самая плотная — «автономные агенты» (12 штук), которые указывают на систему с названием KAIROS.
KAIROS в исходниках упоминается более 150 раз: это режим постоянно работающего фонового демона. Claude Code — это уже не просто инструмент, который отвечает только когда вы его вызываете вручную, а агент, который постоянно работает в фоне: непрерывно наблюдает, записывает и при подходящем моменте сам начинает действовать. При этом условие — не мешать пользователю: любые операции, которые потенциально могут блокировать пользователя дольше 15 секунд, будут выполняться с задержкой.
У KAIROS также встроено распознавание фокуса терминала. В коде есть поле terminalFocus, которое в реальном времени определяет, смотрит ли пользователь в окно терминала. Когда вы переключаетесь на браузер или другое приложение, агент определяет, что вы «не на месте», и переходит в автономный режим: сам выполняет задачи и напрямую отправляет код, не дожидаясь вашего подтверждения. Когда вы возвращаетесь обратно в терминал, агент сразу возвращается в кооперативный режим: сначала сообщает, что сделал, а затем просит ваше мнение. Степень автономности не фиксирована — она в реальном времени колеблется в зависимости от вашего внимания. Это решает давнюю неловкость AI-инструментов: полностью автономный AI не вызывает доверия, а полностью пассивный AI слишком неэффективен. Выбор KAIROS — динамически регулировать инициативность AI вместе с вниманием пользователя: пока вы смотрите — он ведёт себя спокойно, пока вы отвлеклись — он сам начинает работу.
Ещё один подсистемный компонент KAIROS называется autoDream: после накопления 5 сессий или по прошествии 24 часов агент запускает в фоне «процесс размышлений» (reflection), проходящий в четыре шага. Сначала он сканирует уже существующие воспоминания, чтобы понять, что ему сейчас известно. Затем извлекает новые знания из журнала диалога. После этого объединяет новые и старые знания: исправляет противоречия и убирает дубликаты. И наконец сокращает индекс, удаляя устаревшие записи. Эта конструкция заимствует теорию консолидации памяти из когнитивной науки: когда человек спит, он упорядочивает дневные воспоминания, а KAIROS упорядочивает контекст проекта, когда пользователь уходит. Для обычных пользователей это означает: чем дольше вы используете Claude Code, тем точнее он понимает ваш проект — и это не просто «он запомнил, что вы сказали».
Вторая большая категория — «анти-дистилляция и безопасность» (8 flags). Самый заметный из них — механизм fake_tools: когда одновременно выполняются 4 условия (включён compile-time flag, активирован CLI entry, используется first-party API, GrowthBook remote switch true), Claude Code внедряет в API-запросы фиктивные определения инструментов. Цель — загрязнить наборы данных, которые могут быть записаны из API-трафика и использоваться для обучения конкурентных моделей. Это новая форма защиты в гонке вооружений AI: не мешать вам копировать, а заставить вас копировать неправильные вещи.
Кроме того, в коде также встречается кодовое название модели Capybara (она разделена на три уровня: стандартная версия, fast-версия и версия с миллионом контекстного окна). По широко распространённым догадкам сообщества, это внутренний код для серии Claude 5.
Пасхалка: в 512 000 строк кода спрятан электронный домашний питомец
Между всеми серьёзными инженерными архитектурами и механизмами безопасности инженеры Anthropic всё же тихо собрали полноценную систему виртуальных питомцев: внутренний код BUDDY.
Судя по утёкшему коду и анализу сообщества, BUDDY — это терминальный питомец в стиле имитации реальности (拟物化): он появляется вблизи поля ввода пользователя в формате ASCII-пузырей. У него 18 видов (включая водяную свинку, саламандру, грибы, призрака, дракона, а также целый ряд оригинальных существ вроде Pebblecrab, Dustbunny, Mossfrog). Виды разделены на пять уровней по редкости: обычный (60%), редкий (25%), редчайший (10%), эпический (4%) и легендарный (1%). У каждого вида есть «блестящая» (glowing) вариация; самая редкая Shiny Legendary Nebulynx появляется с вероятностью всего одна на десять тысяч.
У каждой BUDDY есть пять параметров: DEBUGGING (отладка), PATIENCE (терпение), CHAOS (хаос), WISDOM (мудрость) и SNARK (ядовитые шутки). Они также умеют надевать шапки: варианты включают корону, цилиндр, шапку с пропеллером, нимб, шляпу волшебника и даже миниатюрную уточку. Хеш значения пользовательского ID определяет, какого питомца высиживаете; Claude сгенерирует для него имя и характер.
Согласно плану релиза из утечки, BUDDY был изначально запланирован к старту внутреннего тестирования с 1 по 7 апреля, а на полноценный запуск — в мае; сначала — для сотрудников Anthropic.
512 000 строк кода, 98,4% — на хардкорную инженерию, но в итоге кто-то всё равно потратил время, чтобы сделать электронного тритона, который надевает шапку с пропеллером. Возможно, именно эта строка кода и является самой человечной в утечке.
Нажмите, чтобы узнать о найме в Lydong BlockBeats
Добро пожаловать в официальное сообщество Lydong BlockBeats:
Telegram подписная группа: https://t.me/theblockbeats
Telegram чат: https://t.me/BlockBeats_App
Twitter официальный аккаунт: https://twitter.com/BlockBeatsAsia
