AI技术渗透到我们生活的方方面面。日益增长的依赖性正在侵蚀我们的控制权。主权AI已经变得至关重要,而非可有可无。Gradient的挑战展示了我们能否实现真正的AI独立。
核心要点
- Gradient将全球闲置的计算资源连接成一个分布式网络。这挑战了少数几家大型科技公司主导的AI行业结构。
- 开放智能堆栈使任何人都能在没有自己基础设施的情况下训练和运行大语言模型。
- 团队成员包括来自加州大学伯克利分校、香港科技大学和苏黎世联邦理工学院的研究人员。他们与Google DeepMind和Meta合作,推动持续进步。
1. 依赖陷阱:AI便利性背后的风险
现在任何人都可以通过与大语言模型对话来构建原型,或者在没有设计经验的情况下生成图像。
然而,这种能力随时可能消失。我们并不完全拥有或控制它。少数几家大公司(OpenAI、Anthropic等)提供了大多数服务运行所依赖的基础设施。我们依赖于他们的系统。
想象一下,如果这些公司撤销大语言模型访问权限会怎样。服务器中断可能导致服务停止。公司可能因各种原因封锁特定地区或用户。价格上涨可能将个人和小型企业挤出市场。

来源:Tiger Research
当这种情况发生时,"无所不能"的能力瞬间变成"一无所能"的无助。日益增长的依赖性放大了这种风险。

来源:Varun Mohan,联合创始人兼CEO,Windsurf
这种风险已经存在。2025年,在竞争对手收购的新闻传出后,Anthropic在没有通知的情况下封锁了AI编码初创公司Windsurf的Claude API访问权限。这一事件限制了部分用户的模型访问权限,并迫使公司进行紧急基础设施重组。一家公司的决定立即影响了另一家公司的服务运营。
这在今天看起来似乎只影响像Windsurf这样的一些公司。随着依赖性的增长,每个人都将面临这个问题。
2. Gradient:以开放智能开启未来

来源:Gradient
Gradient解决了这个问题。解决方案很简单:提供一个环境,让任何人都能以去中心化的方式开发和运行大语言模型,不受限制,使用户摆脱OpenAI或Anthropic等少数公司的控制。
Gradient如何实现这一点?了解大语言模型的工作原理可以阐明这一点。训练创建大语言模型,推理运行它们。
**训练:**创建AI模型的阶段。模型分析海量数据集以学习模式和规则,例如哪些词可能跟在其他词后面,哪些答案适合哪些问题。
**推理:**使用训练好的模型的阶段。模型接收用户问题,并根据学习到的模式生成最有可能的响应。当你与ChatGPT或Claude聊天时,你就在进行推理。
这两个阶段都需要巨大的成本和计算资源。
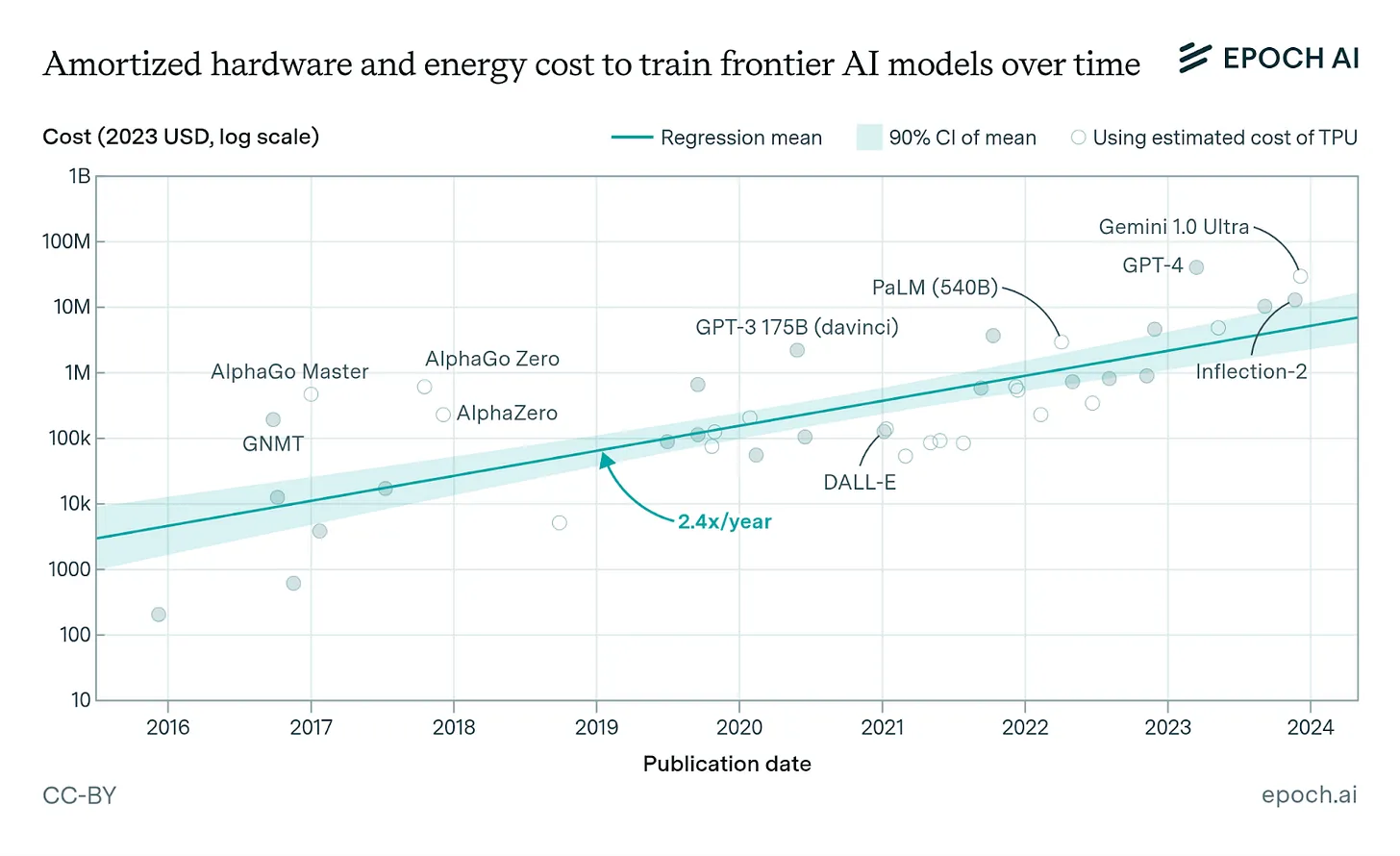
来源:Epoch.ai
仅训练GPT-4估计就花费了超过4000万美元,需要数万个GPU运行数月。推理也需要高性能GPU来生成每一个响应。这些高成本壁垒迫使AI行业整合到资本雄厚的大型科技公司周围。
Gradient以不同的方式解决这个问题。虽然大型科技公司用数万个高性能GPU建造大规模数据中心,Gradient却将全球闲置的计算资源连接成一个分布式网络。家用电脑、闲置的办公服务器和实验室GPU作为一个巨大的集群运行。
这使得个人和小型企业能够在没有自己基础设施的情况下训练和运行大语言模型。最终,Gradient实现了开放智能:AI作为向所有人开放的技术,而不是少数人的专属领域。
3. 实现开放智能的三项核心技术
Gradient的开放智能听起来很吸引人,但实现起来很复杂。全球的计算资源在性能和规格上各不相同。系统必须可靠地连接和协调它们。
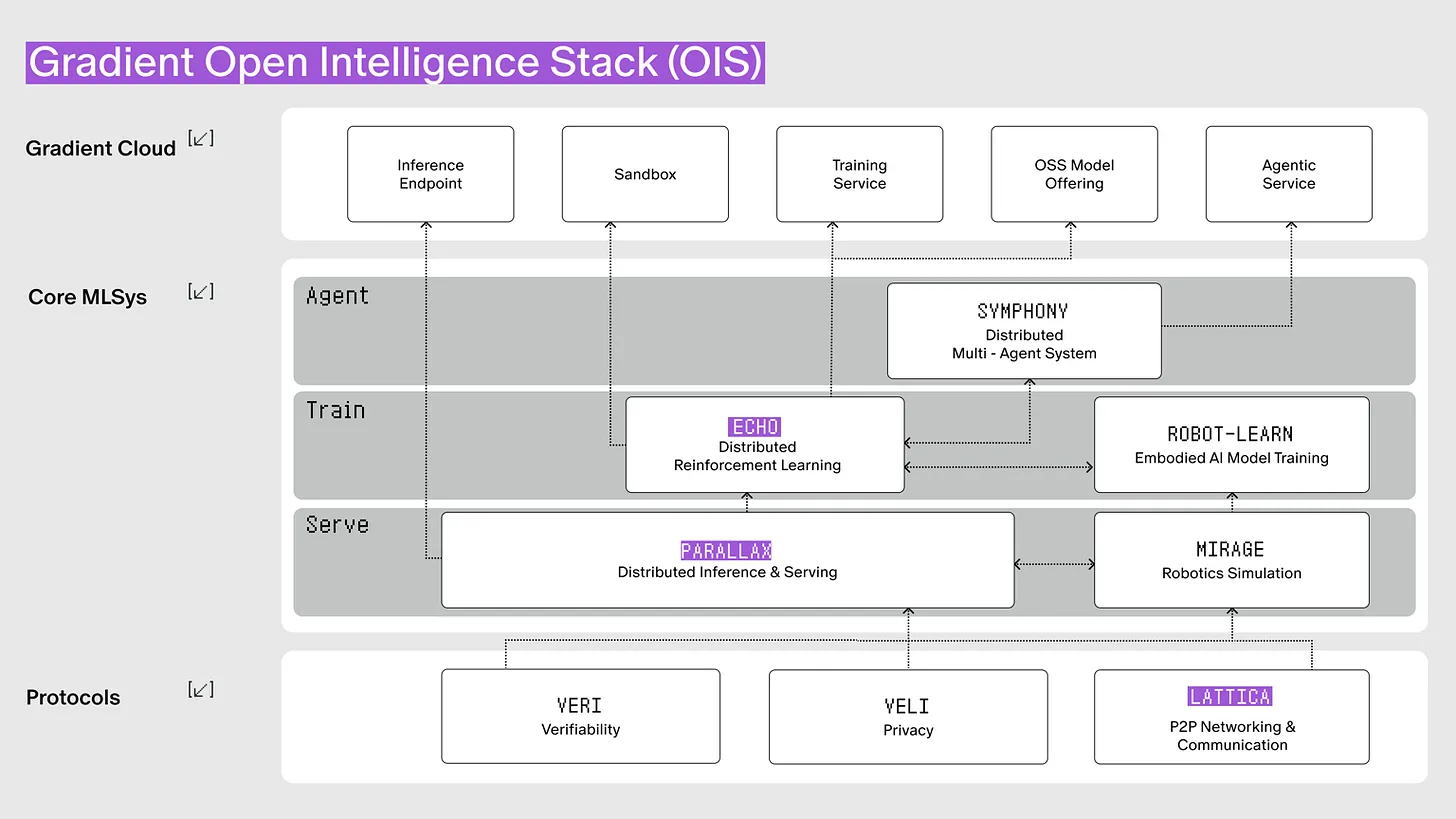
来源:Gradient
Gradient用三项核心技术解决了这个问题。Lattica在分布式环境中建立通信网络。Parallax在这个网络中处理推理。Echo通过强化学习训练模型。这三项技术有机地连接在一起,形成开放智能堆栈。
3.1. Lattica:P2P数据通信协议
中央服务器连接典型的互联网服务。即使我们使用消息应用程序,中央服务器也会转发我们的通信。分布式网络的运作方式不同:每台计算机在没有中央服务器的情况下直接连接和通信。
大多数计算机阻止直接连接并防止外部访问。路由器路由家庭互联网连接,防止外部来源直接定位单个计算机。只用建筑物地址查找特定公寓单元说明了这一挑战。
来源:Gradient
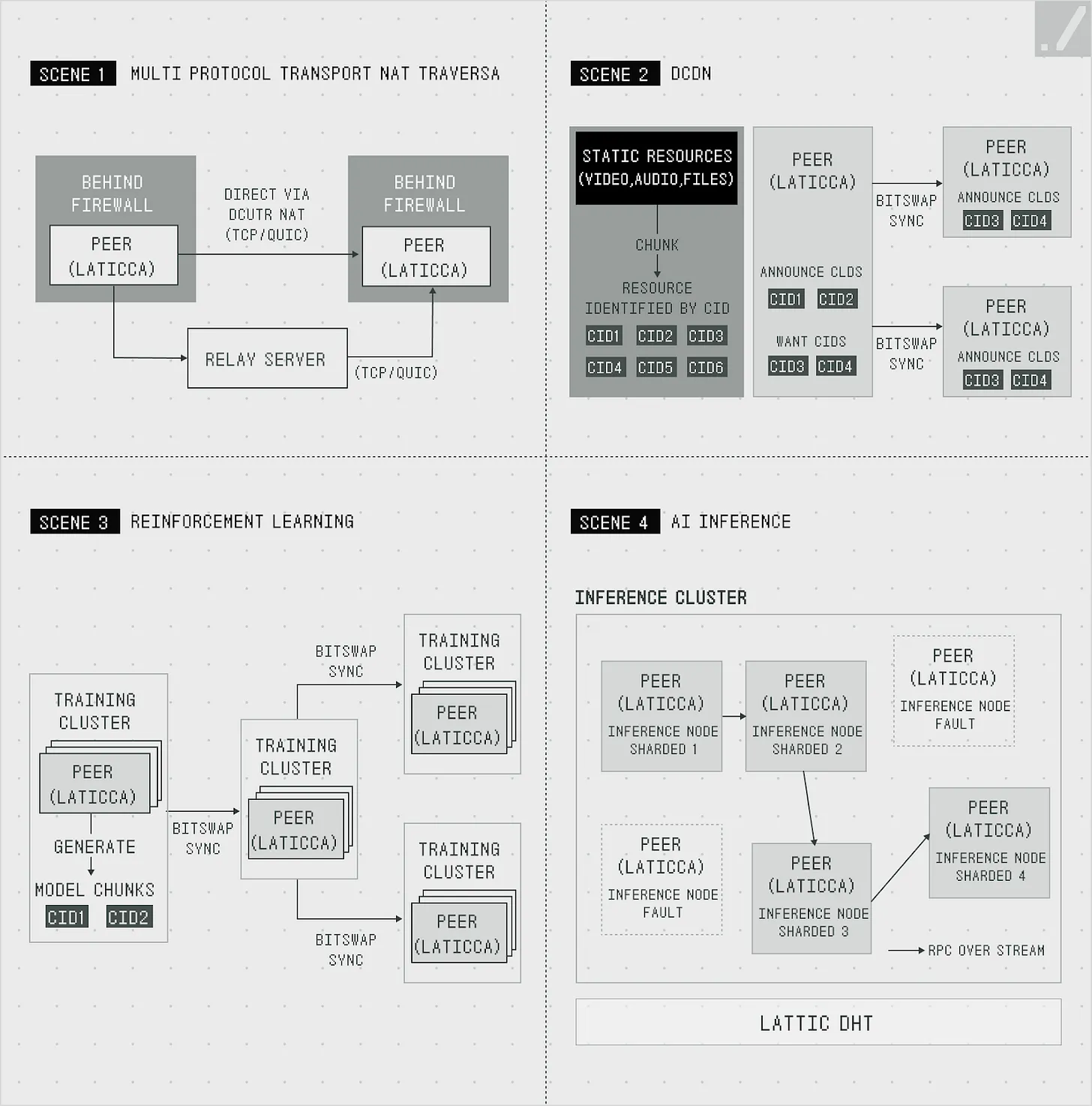
Lattica有效地解决了这个问题。打洞技术通过防火墙或NAT(网络地址转换)创建临时"隧道",实现计算机之间的直接连接。这构建了P2P网络,即使在受限和不可预测的环境中,全球的计算机也能直接连接。一旦连接形成,加密协议就会保护通信安全。
分布式环境需要同时进行数据交换,并在多个节点之间快速同步,以运行大语言模型并传递结果。Lattica使用BitSwap协议(类似于种子)来高效传输模型文件和中间处理结果。
来源:Gradient
Lattica在分布式环境中实现了稳定高效的数据交换。该协议支持AI训练和推理,以及分布式视频流等应用。Lattica的demo展示了它的工作原理。
3.2. Parallax:分布式推理引擎
Lattica解决了连接全球计算机的问题。用户面临一个剩余的挑战:运行大语言模型。开源模型持续进步,但大多数用户仍然无法直接运行它们。大语言模型需要大量的计算资源。即使是DeepSeek的60B模型也需要高性能GPU。
Parallax解决了这个问题。Parallax按层划分一个大型模型,并将它们分布在多个设备上。每个设备处理其分配的层,并将结果传递给下一个设备。汽车装配线的工作方式类似:每个阶段处理一个部分以完成最终结果。
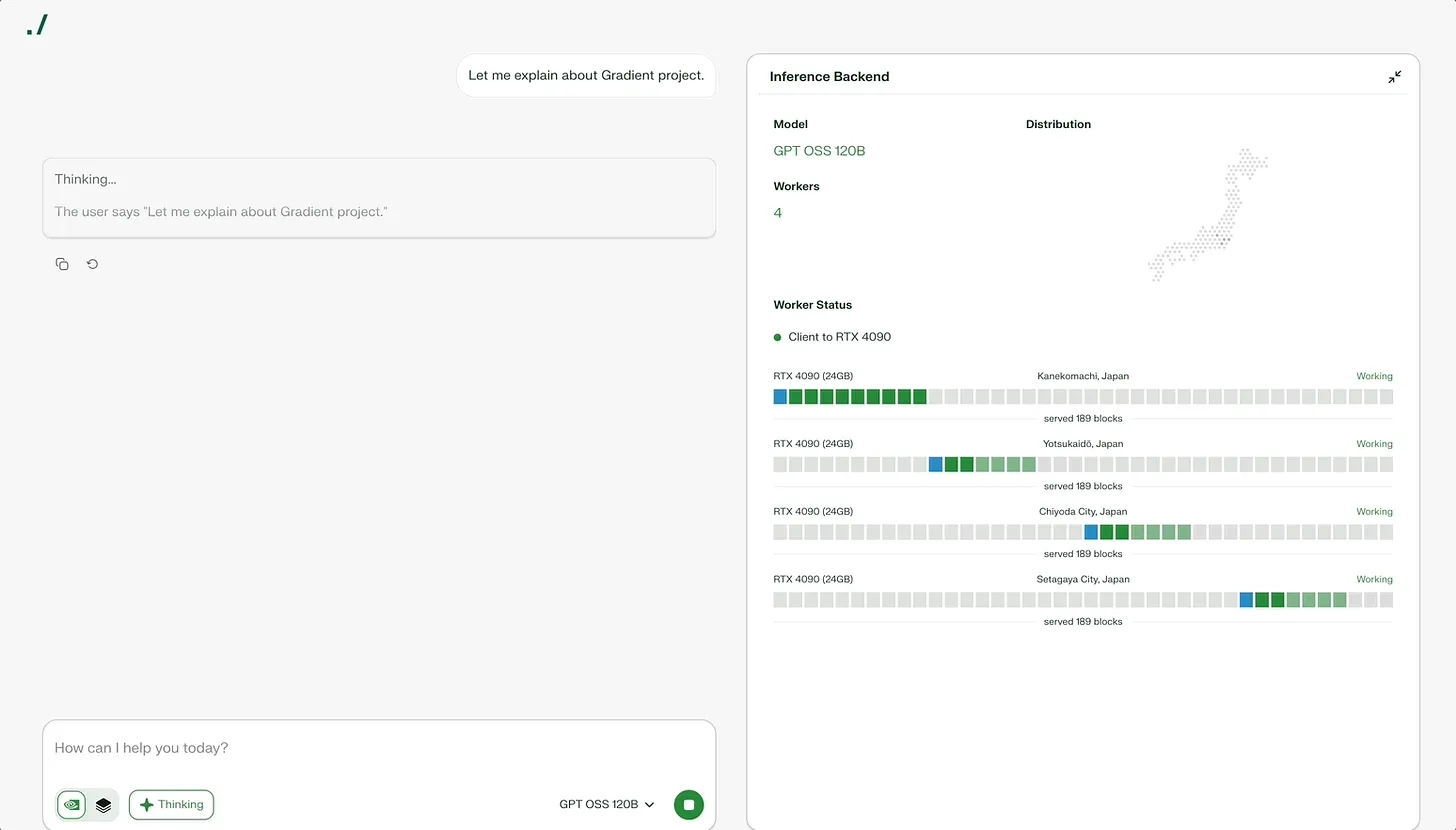
Gradient Chat,来源:Gradient
仅靠划分无法实现效率。参与的设备性能各不相同。当高性能GPU快速处理但下一个设备处理缓慢时,就会形成瓶颈。Parallax实时分析每个设备的性能和速度,以找到最佳组合。系统最大限度地减少瓶颈,并有效利用所有设备。
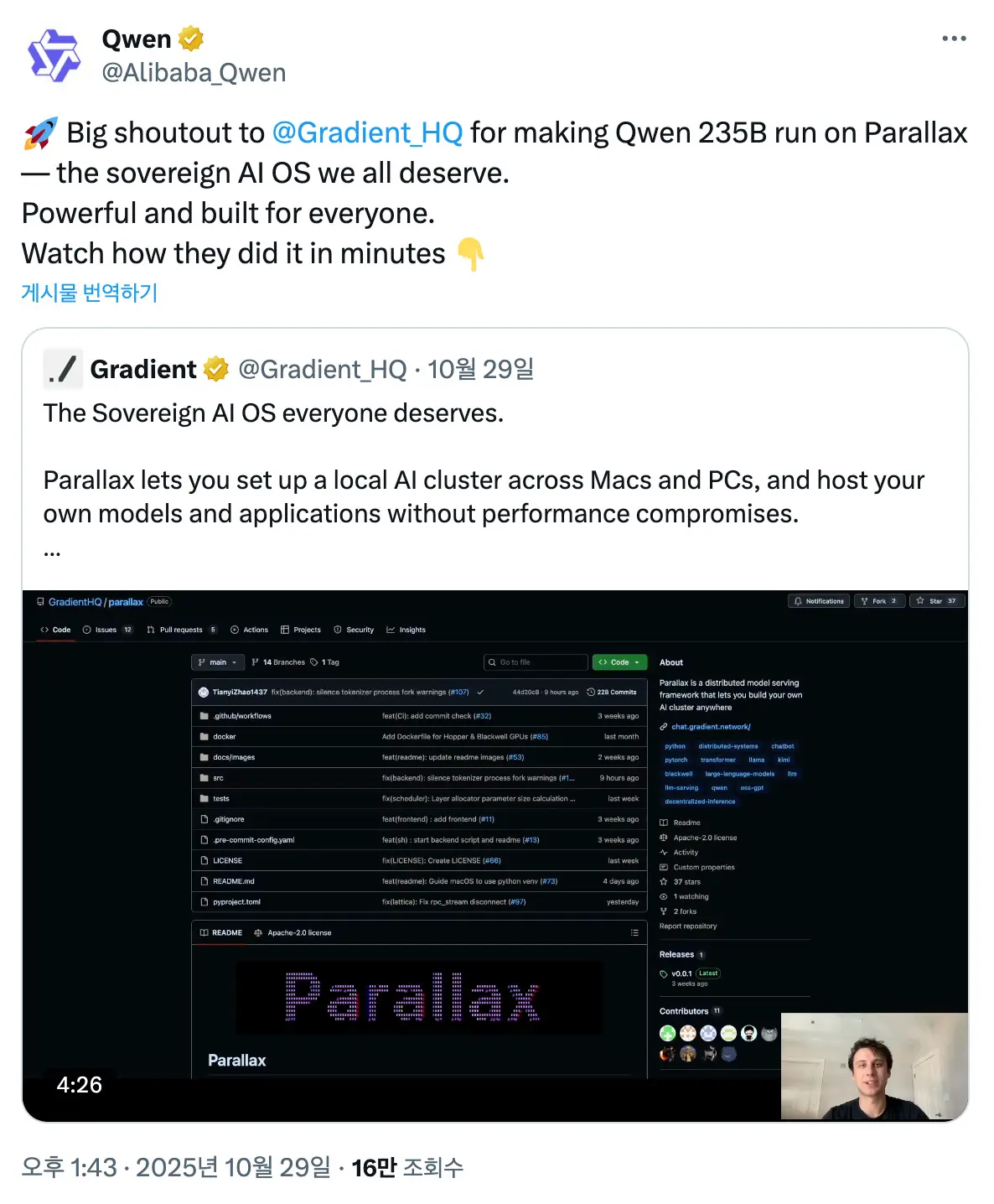
来源:Qwen
Parallax根据需求提供灵活的选项。该系统目前支持40多个开源模型,包括Qwen和Kimi。用户选择并运行他们首选的模型。用户根据模型大小调整执行方法。LocalHost在个人电脑上运行小型模型(如Ollama)。Co-Host在家庭或团队内连接多个设备。Global Host加入全球网络。
3.3. Echo:分布式强化学习框架
Parallax使任何人都能运行模型。Echo解决模型训练问题。预训练的大语言模型限制了实际应用。AI需要针对特定任务进行额外训练才能真正有用。强化学习(RL)提供了这种训练。
强化学习通过试错来教导AI。AI反复解决数学问题,而系统对正确答案给予奖励,对错误答案进行惩罚。通过这个过程,AI学会产生准确的答案。强化学习使ChatGPT能够自然地响应人类偏好。
大语言模型强化学习需要大量的计算资源。Echo将强化学习过程分为两个阶段,并为每个阶段部署优化的硬件。
首先是推理阶段。AI解决数学问题10,000次,并收集正确和错误答案的数据。Echo优先考虑同时运行许多尝试,而不是复杂的计算。
接下来是训练阶段。Echo分析收集的数据,以识别哪些方法产生了好的结果。然后系统调整模型,使AI下次遵循这些方法。Echo在这个阶段快速处理复杂的数学运算。
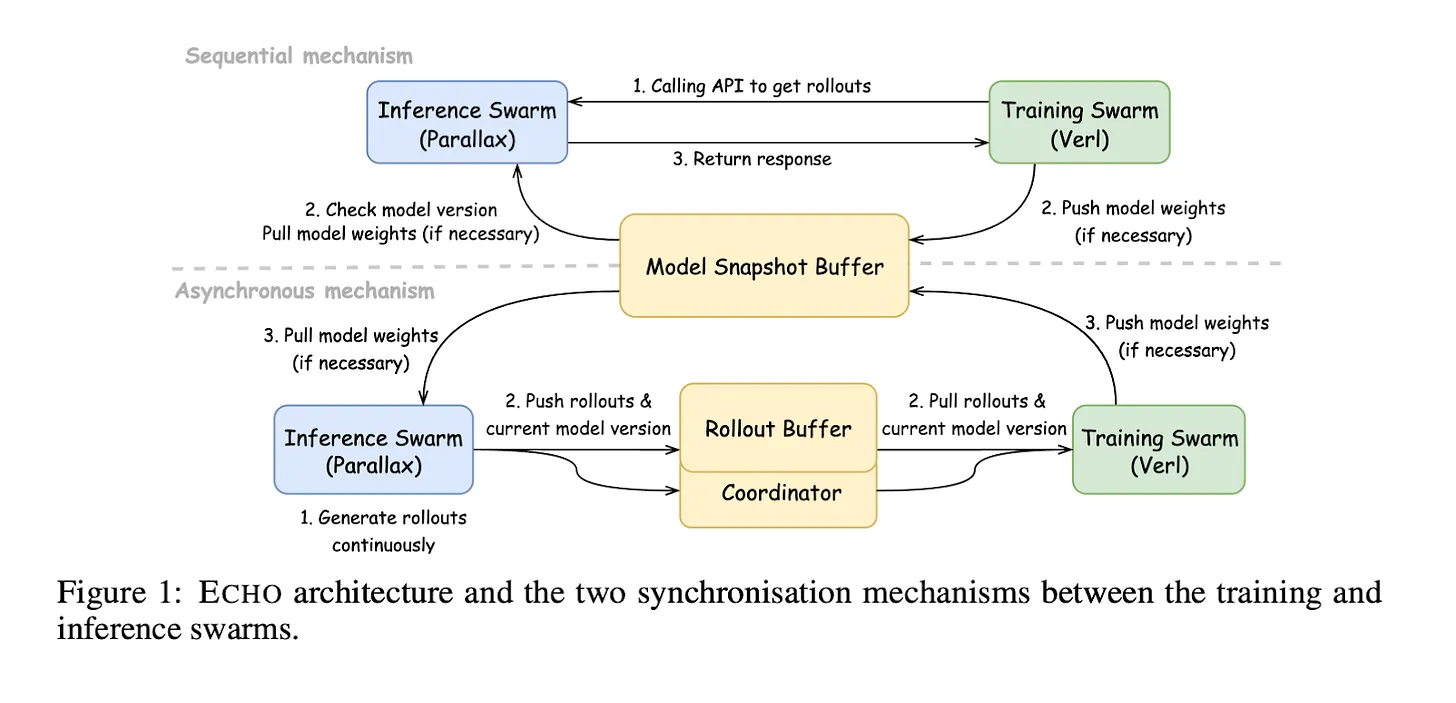
来源:Gradient
Echo将这两个阶段部署在不同的硬件上。推理集群使用Parallax在全球的消费级电脑上运行。RTX 5090或MacBook M4 Pro等多个消费级设备同时生成训练样本。训练集群使用A100等高性能GPU快速改进模型。
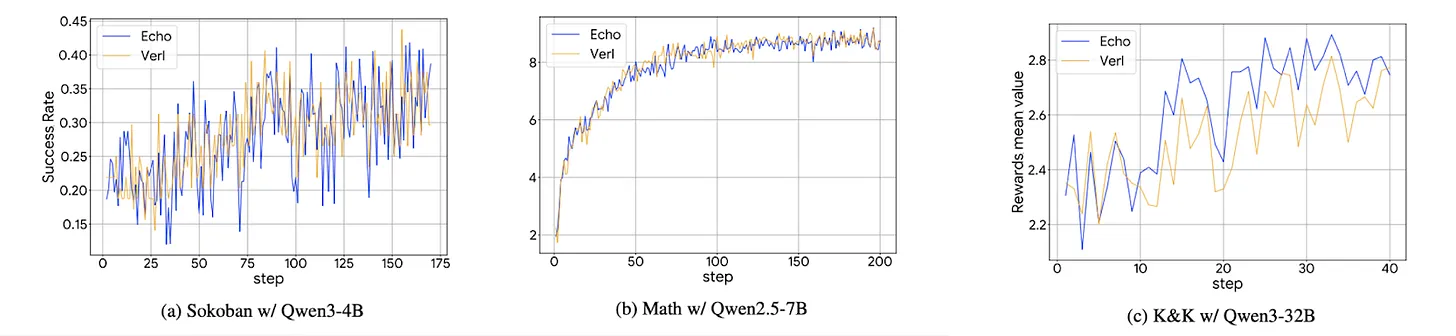
来源:Gradient
结果证明Echo有效。Echo实现了与现有强化学习框架VERL相当的性能。个人和小型企业现在可以在分布式环境中为其特定目的训练大语言模型。Echo显著降低了强化学习的门槛。
4. 主权AI:通过开放智能带来的新可能性
AI已经变得至关重要,而非可有可无。主权AI日益重要。主权AI意味着个人、公司和国家独立拥有和控制AI,而不依赖外部。

来源:Tiger Research
Windsurf案例清楚地证明了这一点。Anthropic在没有通知的情况下封锁了Claude API访问权限。该公司立即面临服务瘫痪。当基础设施提供商封锁访问时,公司遭受即时的运营损害。数据泄露风险使这些问题更加复杂。
国家面临类似的挑战。AI技术在美国和中国周围迅速发展,而其他国家的依赖性日益增长。大多数大语言模型在预训练数据中使用90%的英语。这种语言失衡带来了非英语国家将面临技术排斥的风险。
[正在进行的研究项目]
Veil & Veri:AI的隐私保护和验证层(推理验证、训练验证)
**Mirage:**用于物理世界AI的分布式模拟引擎和机器人学习平台
**Helix:**软件代理(SRE)的自我进化学习框架
**Symphony:**群体智能的多代理自我改进协调框架
Gradient的开放智能堆栈为这个问题提供了替代方案。挑战依然存在。系统如何在分布式网络中验证计算结果?系统如何在任何人都可以参与的开放结构中保证质量和可靠性?Gradient正在进行研究和开发以解决这些挑战。

来源:Gradient
来自加州大学伯克利分校、香港科技大学和苏黎世联邦理工学院的研究人员在分布式AI系统方面持续产出成果。与Google DeepMind和Meta的合作加速了技术进步。投资市场已经认可了这些努力。Gradient在种子轮融资中筹集了1000万美元,由Pantera Capital和Multicoin Capital共同领投,红杉中国(现为HSG)参与投资。
AI技术将变得更加重要。谁拥有和控制它成为关键问题。Gradient正朝着向所有人开放而非被少数人垄断的开放智能方向前进。他们所设想的未来值得关注。
إخلاء المسؤولية: قد تكون المعلومات الواردة في هذه الصفحة من مصادر خارجية ولا تمثل آراء أو مواقف Gate. المحتوى المعروض في هذه الصفحة هو لأغراض مرجعية فقط ولا يشكّل أي نصيحة مالية أو استثمارية أو قانونية. لا تضمن Gate دقة أو اكتمال المعلومات، ولا تتحمّل أي مسؤولية عن أي خسائر ناتجة عن استخدام هذه المعلومات. تنطوي الاستثمارات في الأصول الافتراضية على مخاطر عالية وتخضع لتقلبات سعرية كبيرة. قد تخسر كامل رأس المال المستثمر. يرجى فهم المخاطر ذات الصلة فهمًا كاملًا واتخاذ قرارات مدروسة بناءً على وضعك المالي وقدرتك على تحمّل المخاطر. للتفاصيل، يرجى الرجوع إلى
إخلاء المسؤولية.
